AWSのCloudFrontを設定する方法
AWSのCloudFrontを設定する方法を紹介します。
1.はじめに
Amazon CloudFrontは、AWSが提供する高速で安全なコンテンツ配信ネットワーク(CDN)サービスです。
世界中に分散したエッジロケーションを利用し、Webサイト、動画、APIなどの静的・動的コンテンツをユーザーに低遅延で配信します。
また、キャッシュ機能によりオリジンサーバーの負荷を軽減し、高可用性とセキュリティを実現します。
記事は2回に分けて、1回目はCloudFrontのディストリビューションを作成して、EC2インスタンスのサーバにアクセスするところまでの手順を説明します。
2.ディストリビューション作成
AWSコンソールのホームから「すべてのサービスを表示」をクリック。
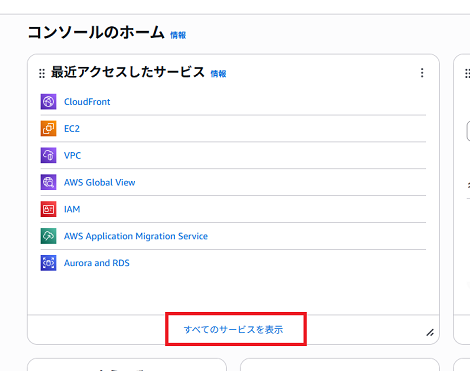
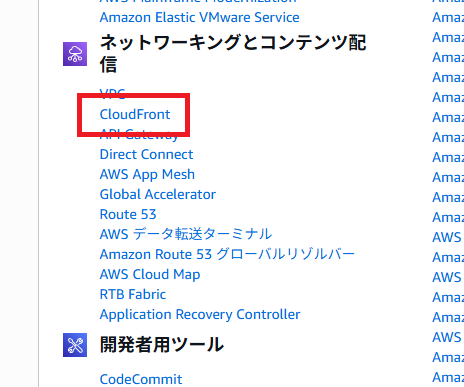
「ネットワーキングとコンテンツ配信」のカテゴリより「CloudFront」をクリック。
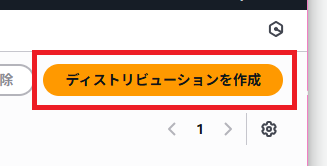
「ディストリビューションを作成」をクリック。ひとつのディストリビューションでひとつのCloudFrontのドメインが割り当てられます。
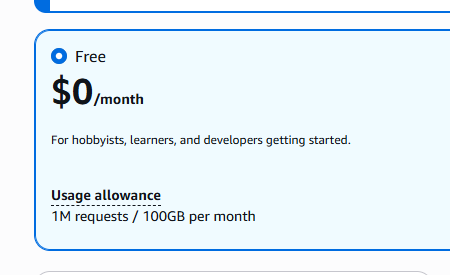
プランの選択画面になるので、ここでは「Free」を選択します。
「Next」をクリック。

「Distribution name」に任意の名称、「Distribution type」は「Single website or app」を選択します。
「Next」をクリック。
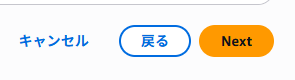
origin type:otherを選択
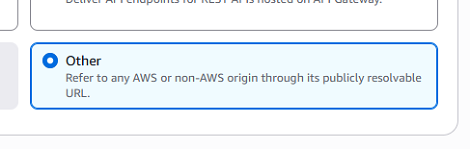
Custom origin:EC2インスタンスの「パブリックDNS」を設定
Origin path:空白のまま
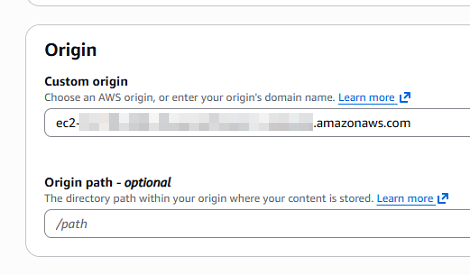
「Setting」は「Cutomize origin settings」を選択したあと、下記を設定しました。
- プロトコル:httpのみ
- Origin IP address type:IPv4-only
「Cache settings」も「Cutomize cache settings」を選択したあと、下記を設定しました。
- キャッシュポリシー:CachingDisabled
など。
(一度拡大したあと、画像の右下あたりをクリックすると最大化します)
「Enable security」は何も使わないのでデフォルトのままとします。
(クリックで拡大)
最後に確認画面が表示されるので問題なければ「Create distribution」をクリック。

2.ディストリビューションドメイン名の確認
左上の「ディストリビューションドメイン名」が、CloudFrondから割り当てられたドメイン名になります。
(クリックで拡大)
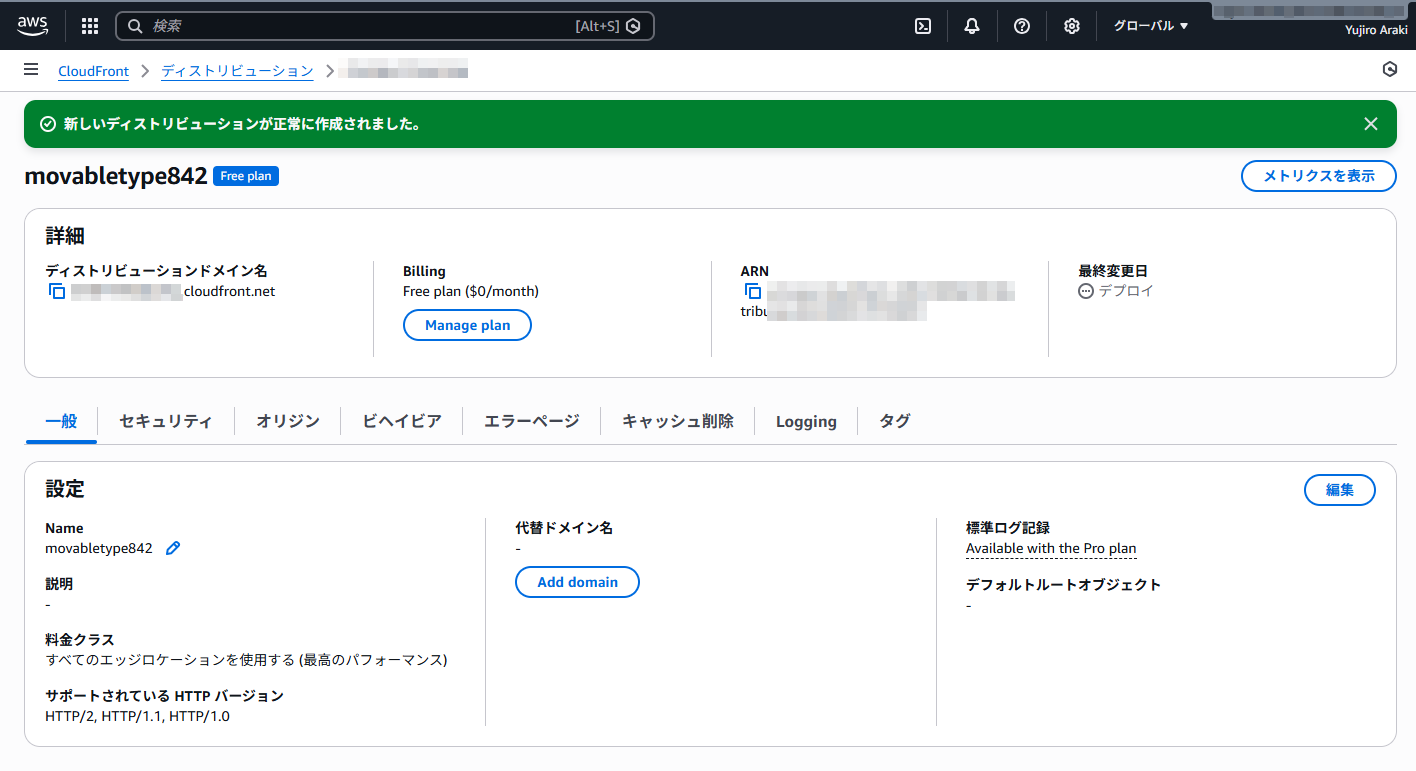
3.CloudFrontのドメインによるアクセス
ブラウザのURLについて、EC2インスタンスのパブリックIPv4アドレス(下記)をこのドメインに変更することで、CloudFront経由でのアクセスになります。

AWS SES(Amazon Simple Email Service)とSMTPを設定する方法
EC2サーバーにインストールしているMovableTypeからメールを送信したいので、AWS SES(Amazon Simple Email Service)とSMTPを設定してみました。

2026年2月現在の情報で、テスト用メールのため、設定は最低限です。
前半はSESの設定なので、MovableType以外の用途の方にも役立てば幸いです。
SESにはIAMユーザーが必要となりますが、設定の中で自動的に作成されるようです。
1.SES設定
AWSホームで「すべてのサービス」をクリックした先にある「Amazon Simple Email Service」をクリック

「使用を開始」をクリック
検証用メールアドレスを設定して「次へ」をクリック。検証用メールアドレスは実際に自分で受信できるアドレスを設定します。

送信ドメイン(実際に利用しているドメイン)を設定して、MAIL FROM ドメインに「mail(.koikikukan.com)」を設定して「次へ」をクリック。
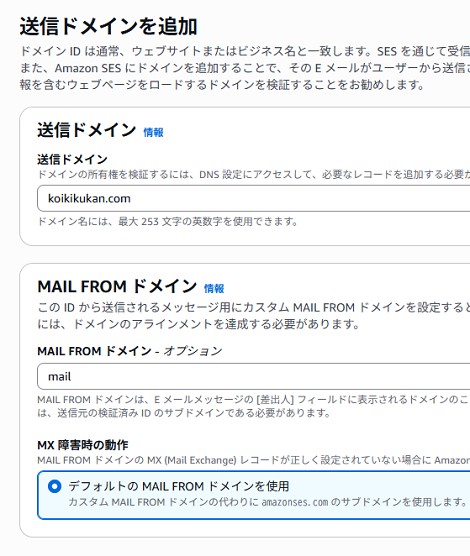
ドメインはレンタルサーバなどで取得しているドメインを設定する必要があります。ここではこのサイトの「koikikukan.com」を設定します。
このドメインは「さくらインターネット」で利用しているので、このあとの手順でドメインに対応するメールサーバの設定を行います。
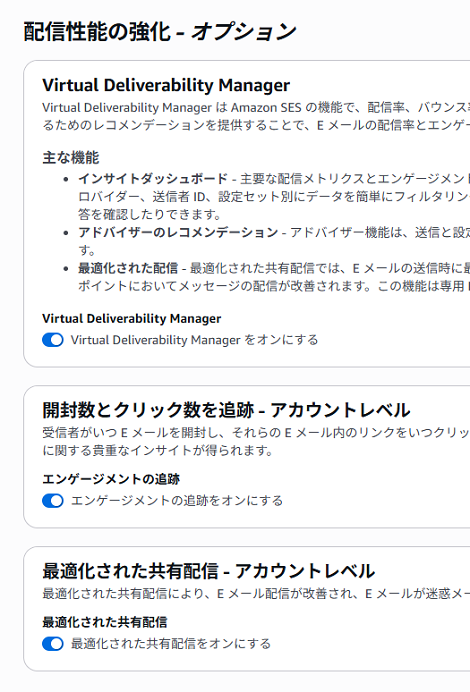
「配信性能の強化」での、
- Virtual Deliverability Manager
- 開封数とクリック数を追跡
- 最適化された共有配信
はすべてオンのまま「次へ」をクリック。
「専用 IP プールを作成」はオフのまま「次へ」をクリック。
「テナント管理」は設定せず「次へ」をクリック。

SESの設定内容を確認して「使用を開始」をクリック。

ここまで設定すると、次に「未解決のタスク」が表示されます。
(クリックで拡大、ドラッグ可能)
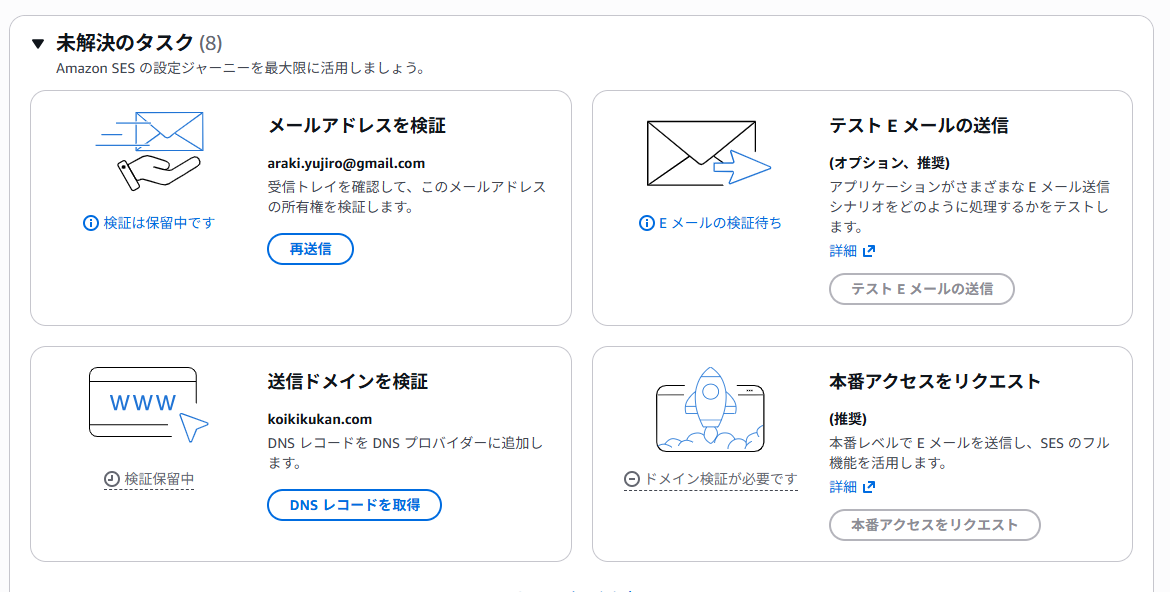
この中で最初に着手するのは「送信ドメインを検証」で、「DNSレコードを取得」をクリック。
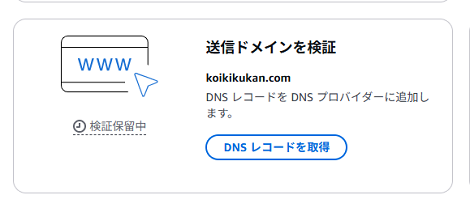
2.DNS設定(レンタルサーバ側)
ここからはさくらインターネットの設定画面で、SESが送信ドメイン検証を実施するための設定を説明します。
今回の手順の中で一番悩んだところです。
手順としてまとまっていないのでポイントのみ。
サーバーコントロールパネルの「ドメイン/SSL」→「ドメイン/SSL」をクリック。
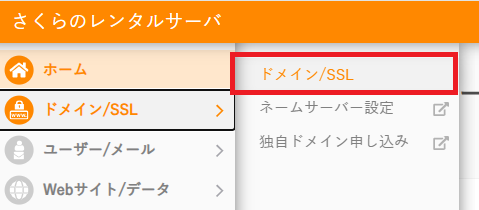
サーバで利用しているドメインの一覧が表示されるので、今回利用するドメインの右側にある「設定」→「DNSレコード設定」をクリック。
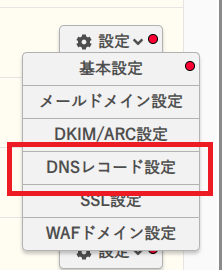
レコード情報が表示されるので、SESの「DNSレコードを取得」をクリックしたときに表示される内容(下記)をここに追加していきます。
(クリックで拡大、ドラッグ可能)
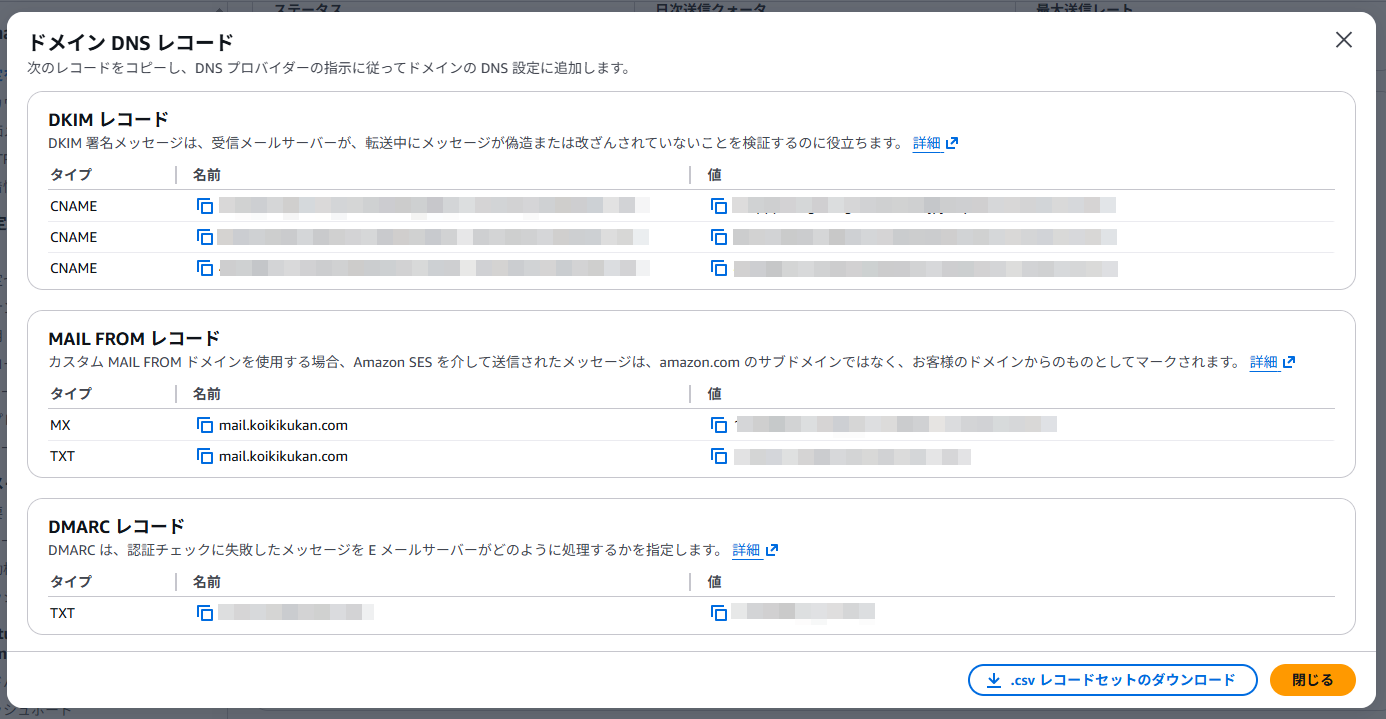
さくらインターネットのDNS表示は次のようになっています。
- グレー部分:SESの各XXレコードの「名前」
- TXTやMX:SESの各XXレコードのタイプ
- テキストフィールドまたはテキストエリア:SESの各レコード+タイプの「値」
(クリックで拡大、ドラッグ可能)
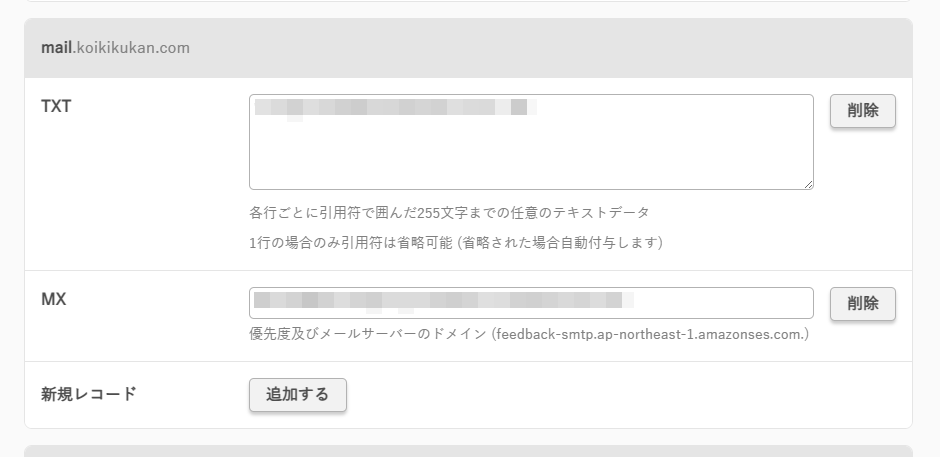
設定は「名前」→「タイプ」→「値」の順で設定してします。
「名前」を一覧に新たに追加するには、一覧の一番下に「新規エントリー」があるので、「追加する」をクリック。
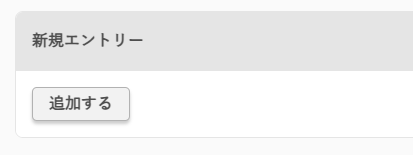
表示されたダイアログに「レコード名」を設定して「追加する」をクリックすれば、タイプ(レコード種別)や値を設定できます。
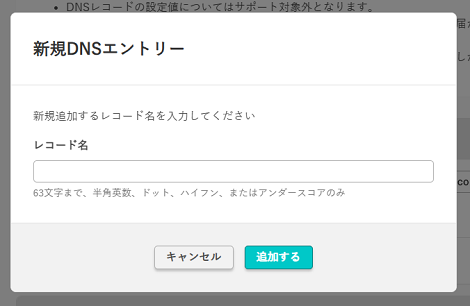
既存の一覧に「名前」がすでにある場合は、その中の下にある「新規レコード」を追加して、タイプ(レコード種別)と値を設定します。

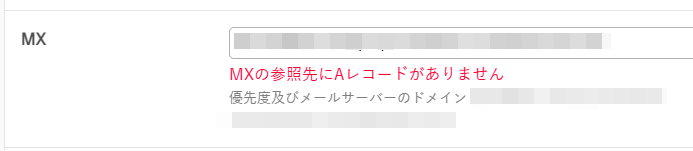
なお、値を設定したときに「~の参照先にAレコードがありません」というエラーが表示される場合、値の最後にピリオドを付与することで解消します。
(クリックで拡大、ドラッグ可能)
SESの方では自動的に検証しているようで、DNSレコードのすべての設定が終わって少しすると「検証済」になるようで、これで設定OKです(「未解決のタスク」から「完了したタスク」に自動的に移動します)。
3.検証用メール送信
また、DNS検証が「検証済」になると、最初に登録した検証用メールアドレスに検証メールが自動的に送信されるので、メールに記載されたリンクをクリックすれば「メールアドレスを検証」が検証済になります(「未解決のタスク」から「完了したタスク」に自動的に移動します)。

4.本番リクエスト
ここまでOKになれば、SESの「本番アクセスをリクエスト」をクリック。
下記を設定し、「了解」をチェックして「リクエストの送信」をクリック。
- リクエストタイプ:トランザクション
- ウェブサイトの URL:ドメインのURL
- その他の連絡先:任意
- 連絡する際の希望言語:Japanese
(クリックで拡大、ドラッグ可能)
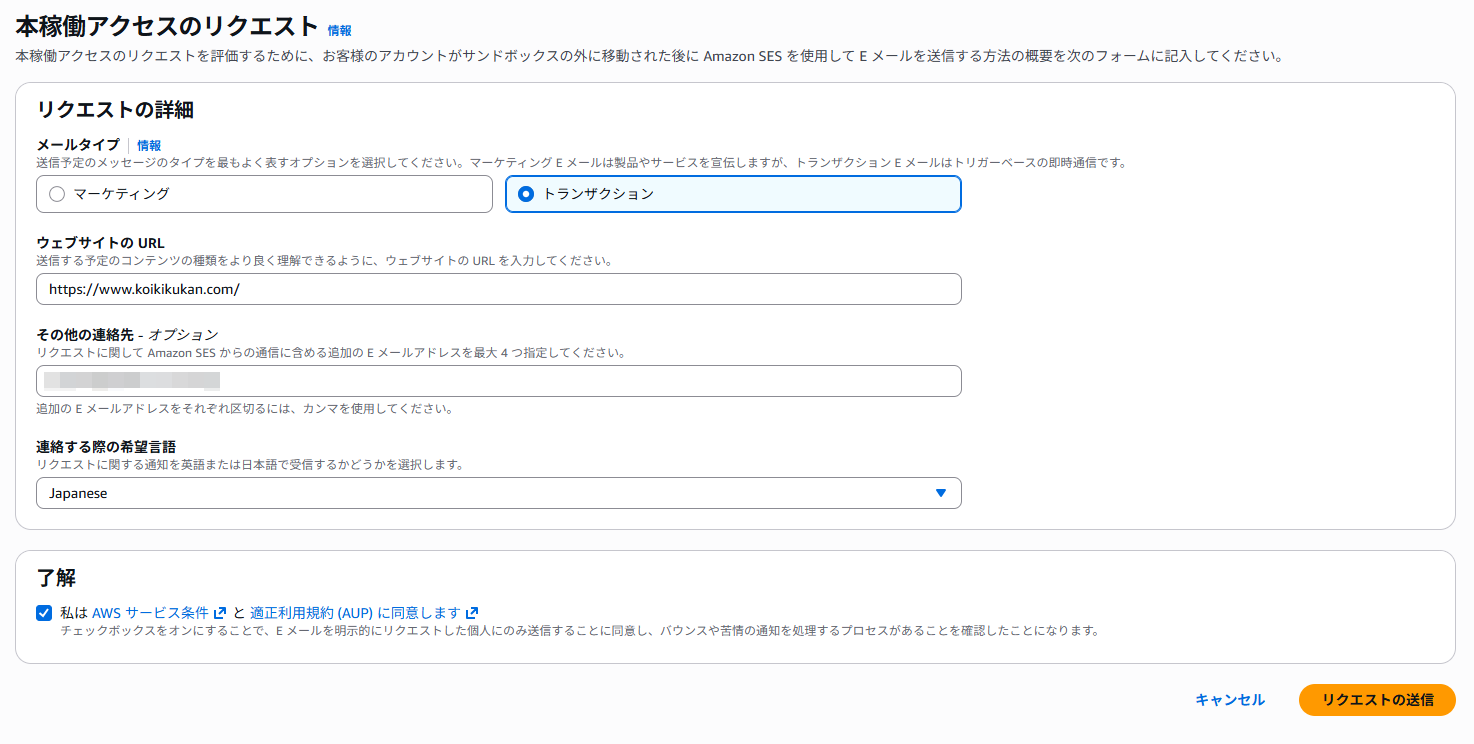
私の場合、リクエストは数分で有効化されました。
5.SMTP設定
あとは設定したSESを送信メールサーバとして振舞うためのSMTP設定です。
SESのメニュー左にある「SMTP設定」をクリック。
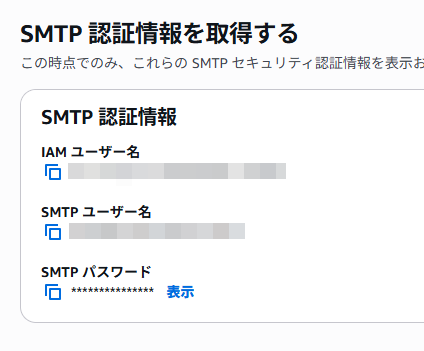
「SMTP認証情報の作成」をクリック。
表示された「ユーザー名」と「ユーザーグループ名」は変更せずに、右下の「ユーザーの作成」をクリック。
(クリックで拡大、ドラッグ可能)
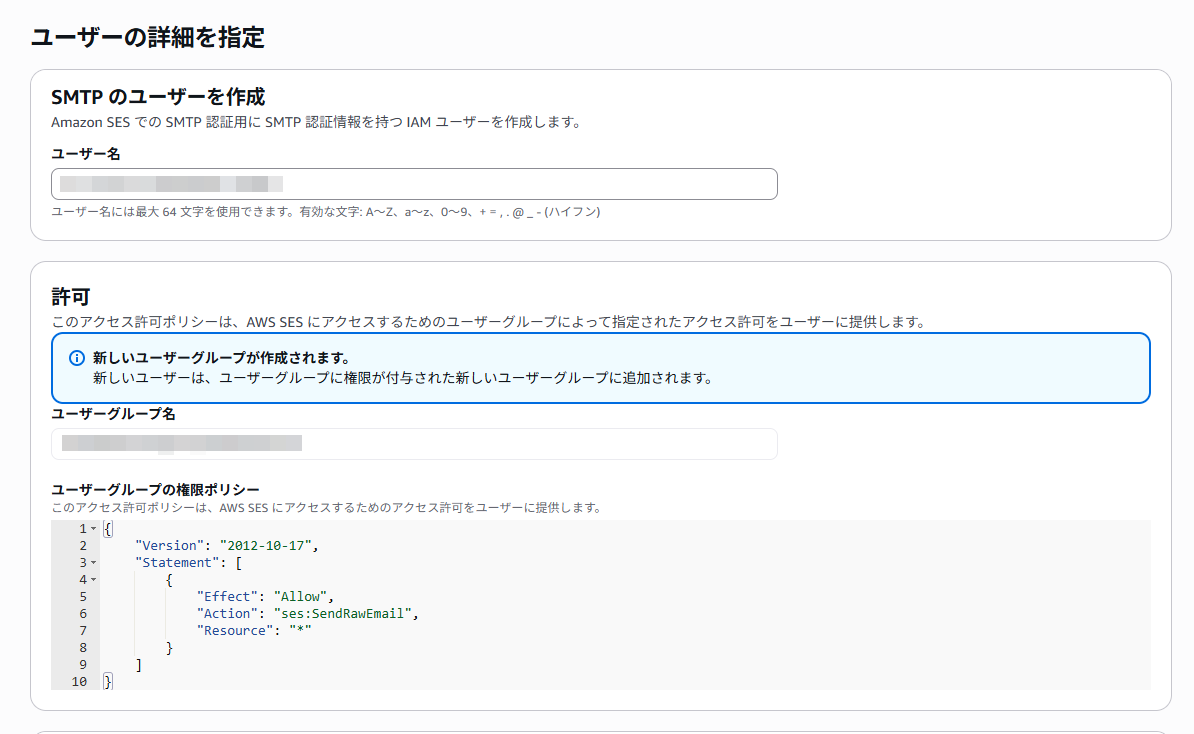
ユーザーを作成すると、SMTP認証に必要な情報が表示されます。パスワードはこの画面でしか表示されないので「表示」をクリックし、表示内容を別の場所に保存してください。
6.MovableTypeにSMTP情報を設定
MovableTypeからメール送信できるようにするため、前項の内容をmt-config.cgiに追加します。
追加する内容は下記です。
MailTransfer smtp
SMTPServer <SMTPエンドポイント>
SMTPPort 587
SMTPAuth starttls
SMTPUser <SMTP認証情報のSMTPユーザー名> ※「IAMユーザー名」ではありません
SMTPPassword <SMTP認証情報のSMTPパスワード>
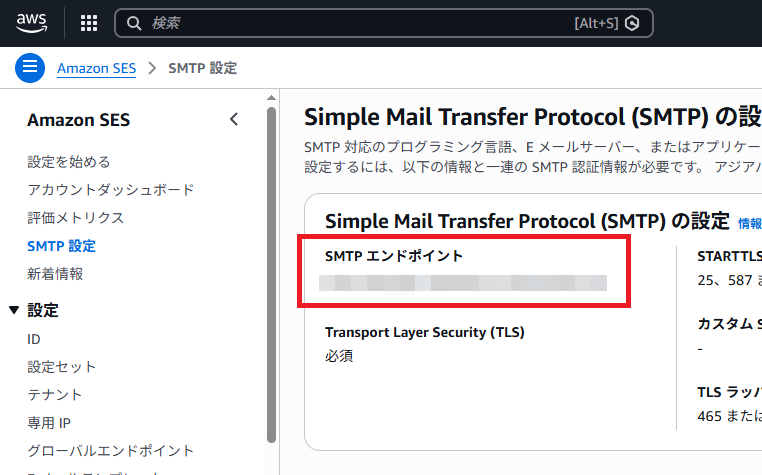
SMTPServerの設定内容は、「Amazon SES」→左メニューの「SMTP設定」をクリックしたときに表示される「SMTPエンドポイント」です。
(クリックで拡大、ドラッグ可能)
CSVDataImExporterプラグイン・セキュリティアップデート
Category:[インポート・エクスポート]
Tag:[CSVDataImExporter, MovableType, Plugin]
Permalink
CSVDataImExporterプラグインをセキュリティアップデートしました。
1.概要
MovableTypeの下記のセキュリティアップデートに伴い、CSVDataImExporterプラグインも環境変数、
に対応しました。
CSV ファイルのエクスポート機能において、数式インジェクション対策を行いました。セルが特定の文字で始まる場合にエスケープ処理を行う環境変数 CSVExportEscapeFormula と、BOM の有無を制御する環境変数 CSVExportWithBOM を追加しました (CVE-2026-24447, MTC-30835)
上記に対応するCSVDataImExporterプラグインのバージョンは下記の通りです。
- 通常版:5_67
- 機能拡張版:6_41
- アセットアップロード版:7_22
- アセットアップロード+機能拡張版:8_22
3.対応MTバージョン
これらのバージョンは、MT8およびMT9の、
- MT-8.0.9
- MT-9.0.6
以上のバージョンでご利用になれます。
4.機能変更について
プラグインのバージョンアップに伴い、下記の機能変更があります。
- エクスポート時、UTF-8選択時のBOMチェックを削除しました(CSVExportWithBOMの設定に依存)
- インポート時の動作として「エクスポート時に付与したエスケープを除去」を追加しました(サイト別およびシステム管理画面のプラグイン設定)

2.CSVDataImExporterプラグインについて
CSVDataImExporterプラグインの詳細は下記のリンクよりご覧ください。


