WindowsでRGB画像をCMYK画像に変換する方法
WindowsでRGB画像をCMYK画像に変換する方法を紹介します。
1.はじめに
GIMPを使って画像を加工していたのですが、加工した画像がRGBカラーでした。
GIMPではRGBからCMYKに変換することができないようです。
ということで、WindowsでRGB画像をCMYK画像に変換する方法を紹介します。
2.RGB画像をCMYK画像に変換する
RGB画像をCMYK画像に変換するには「KRITA(クリータ、クリタ)」という、オープンソースソフトウェアのペイントソフトを使用します。
インストール手順は省略します。
使用しているKRITAのバージョンは5.2.9です。
KRITAを起動し、CMYKに変換したい画像を「ファイル」→「開く」で開きます。
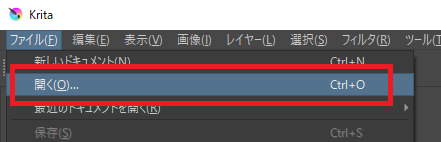
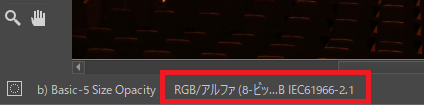
開くと下部に「RGB~」と表示されていると思います。
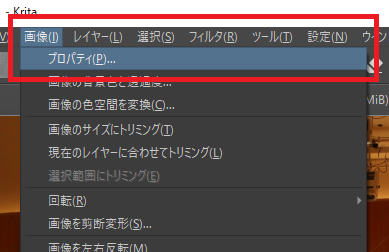
「画像」→「プロパティ」を選択。
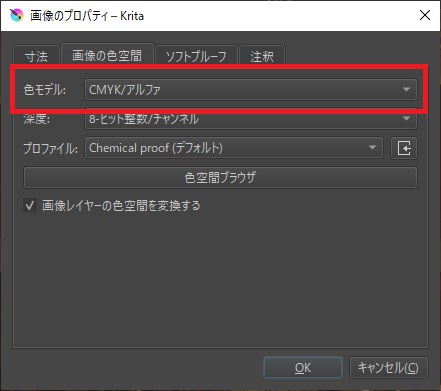
「画像の色空間」タブをクリック。
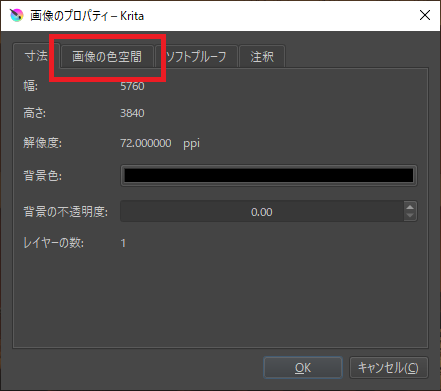
「色モデル」を「RGB~」から「CMYK~」に変更して「OK」をクリック。
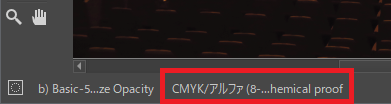
下部の表示が「CMYK~」に変わっていることを確認。
あとは「ファイル」→「保存」で上書きするか「名前をつけて保存」で別名で保存すれば完了です。
AWSでIAMユーザーを作成する方法
AWSでIAMユーザーを作成する方法を紹介します。
1.はじめに
AWSに久しぶりにアクセスしてみると、ログイン画面が「アカウントID」と「IAMユーザー」に変わっていました。
IAMユーザーというものをそもそも作っていなかったので、本記事で作成方法を紹介します。
なお、アカウントIDは後述するルートユーザーでログイン後、右上のユーザー名をクリックすれば「アカウントID」が表示されます。
2.AWSでIAMユーザーを作成する
AWSマネジメントコンソールにアクセス。
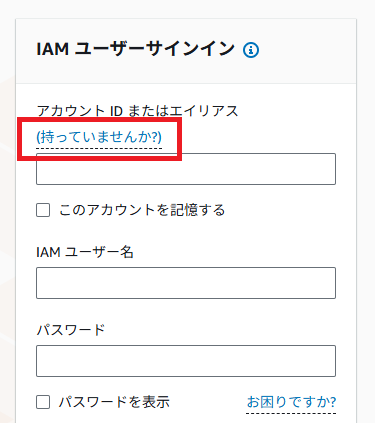
「持っていませんか?」のリンクをクリックすればルートユーザーでログインできる画面に切り替わるので、ルートユーザーでログインします(詳細は省略)。
ログイン後、左上の「IAM」を選択
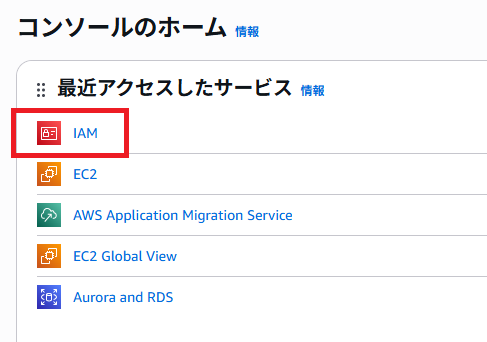
「ユーザー」をクリック。
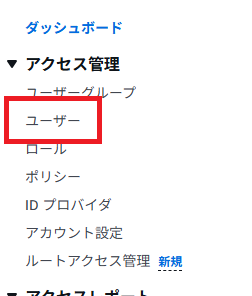
「ユーザーの作成」をクリック。
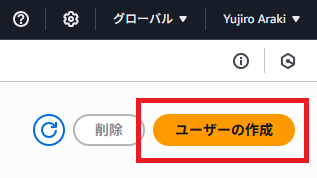
任意のユーザー名を設定して、「ユーザータイプ 」から「IAM ユーザーを作成します」を選択。パスワードの作成方法は任意。
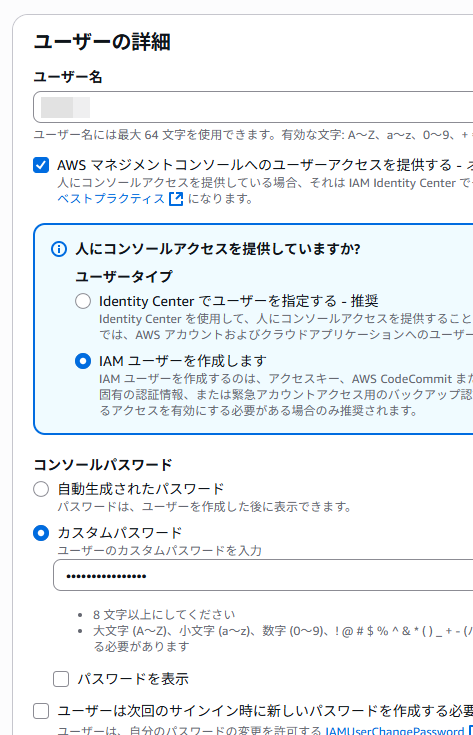
すべて設定後「次へ」をクリック。

今回は1ユーザーで、ユーザーグループを作成しないので、「ポリシーを直接アタッチする」を選択。
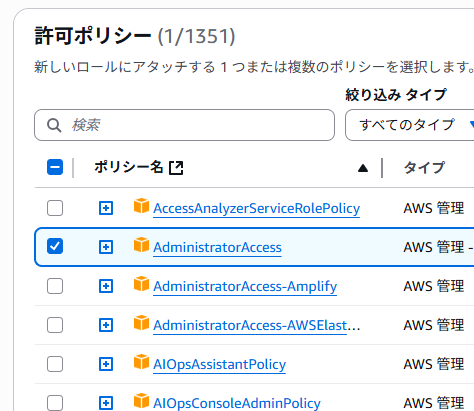
作成するユーザーにすべての権限を与えたいので、「AdministratorAccess」のみをチェック。その下の「許可の境界を設定」はスキップします。
すべて設定後「次へ」をクリック。
設定した内容の確認画面が表示されるので、問題なければ「ユーザーの作成」をクリック。
「ユーザーが正常に作成されました」が表示されれば完了です。コンソールサインインURLやパスワードも表示されます。

なお、これまでルートユーザーで作成したものは、別ユーザーなので一切表示されないようです。
ansibleで同名のroleを複数回実行する方法
ansibleで同名のroleを複数回実行する方法を紹介します。
1.問題点
次のroleを作成しました。
roles/test/tasks/main.yml
- name: コマンド実行
shell:
cmd: hostname
register: result
- name: 結果出力
debug:
msg: "{{ result.stdout_lines }}"このroleを実行するplaybook(test.yml)は下記です。
- hosts: localhost
connection: local
roles:
- role: test
- role: test
- role: testinventoryは省略しますので適宜用意してください。
このplaybookを実行すると、roleは一度しか実行されません。
(ansible) [hoge@server ~]$ ansible-playbook -i inventory test.yml
PLAY [localhost] ********************************************************************************************************************
TASK [Gathering Facts] **************************************************************************************************************
ok: [localhost]
TASK [test : コマンド実行] **********************************************************************************************************
changed: [localhost]
TASK [test : 結果出力] **************************************************************************************************************
ok: [localhost] => {
"msg": [
"hoge-server"
]
}
PLAY RECAP **************************************************************************************************************************
localhost : ok=3 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=02.原因
これは、Ansibleが「ロールの重複適用」を避ける設計になっているためです。
3.対処
いくつか方法はあるようですが、ここではplaybook内で「tags」を付与する方法を紹介します。
下記のように、roleごとにtagsを追加して、ユニークな値を設定します。
test.yml
- hosts: localhost
connection: local
roles:
- role: test
tags: "1"
- role: test
tags: "2"
- role: test
tags: "3"これで同名のroleでも期待通り実行されます。
(ansible) [hoge@server ~]$ ansible-playbook -i inventory test.yml
PLAY [localhost] ********************************************************************************************************************
TASK [Gathering Facts] **************************************************************************************************************
ok: [localhost]
TASK [test : コマンド実行] **********************************************************************************************************
changed: [localhost]
TASK [test : 結果出力] **************************************************************************************************************
ok: [localhost] => {
"msg": [
"hoge-server"
]
}
TASK [test : コマンド実行] **********************************************************************************************************
changed: [localhost]
TASK [test : 結果出力] **************************************************************************************************************
ok: [localhost] => {
"msg": [
"hoge-server"
]
}
TASK [test : コマンド実行] **********************************************************************************************************
changed: [localhost]
TASK [test : 結果出力] **************************************************************************************************************
ok: [localhost] => {
"msg": [
"hoge-server"
]
}
PLAY RECAP **************************************************************************************************************************
localhost : ok=7 changed=3 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
