CSVDataImExporterプラグイン(アセットアップロード・ダウンロード対応版)
CSVDataImExporterプラグイン(アセットアップロード・ダウンロード対応版)をリリースしました。
1.概要
コンテンツデータのアセットフィールドに紐づいているアセット(画像・オーディオ・ビデオ・ファイル)をCSVファイルとペアでダウンロードすることが可能です。
また、CSVのインポート時にアセットをあわせてアップロード(ZIP形式)することで、アセットの登録と、CSVのコンテンツデータのアセットフィールドとの関連づけが同時に行えます。
注:2025年9月現在、記事アセットおよびカスタムフィールドに対しての機能追加はありません。
2-1.エクスポート機能(コンテンツデータ一覧画面)
コンテンツデータ一覧画面の「アクション」に「 コンテンツデータのエクスポート・アセットダウンロードつき(ZIP) 」というメニューを追加しました。
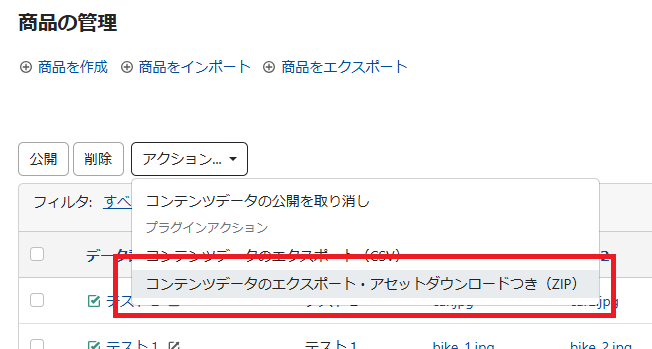
この項目を選択してCSVをエクスポートすると、ZIP形式でのダウンロードとなり、ZIPファイルの内容は次のようになります。
export-001-002-20250816152706.zip
├─ export-001-002-20250816152706.csv ← CSVファイル
└─ ASSET_DIR/ ← アセット格納用フォルダ
├─ assets/
│ └─ 2025/
│ └─ 09/
│ ├─ file1.jpg
│ └─ file2.jpg
├─ images/
│ └─ file2.webp
└─ s-l960.pdfまた、CSVのアセットフィールドには、下記のように「パス+ファイル名」で設定されます(赤字部分)。
content_type,id,label,author_id,identifier,authored_on,modified_on,unpublished_on,status,名前,画像1,画像2
商品,1,テスト1,1,2b909dd37403b295ff80f6f46d23fd72cebf41d5,2025/8/6 0:58,2025/8/22 23:06,,2,テスト1,assets/2025/09/file1.jpg,s-l960.pdf
商品,2,テスト2,1,f46d23fd72cebf41d5295ff80f6f4609dd37403b,2025/8/6 0:58,2025/8/22 23:06,,2,テスト2,assets/2025/09/file2.jpg,images/file2.webp2-2.エクスポート機能(エクスポート画面)
エクスポート画面にも「アセットダウンロードつき(ZIP) 」というメニューを追加しました。

チェックすればすべてのコンテンツデータにひもづくアセットをダウンロードします。
注:サーバ環境やアセット数・合計サイズによって正常にエクスポートできない可能性があります。
3.インポート機能
インポート画面に「ZIPファイルのアセット 」というメニューを追加しました。

基本動作は、ZIPファイルを指定してインポートすれば、CSVのアセットフィールドに記載されたパス・ファイル内を使って、ZIPのASSET_DIR配下に存在するアセットをアップロードしながら、コンテンツデータのアセットフィールドとひもづけていきます。
そのため、すでに同一パス・ファイルのアセットがサイトに存在する場合の挙動を追加したメニューで指定します。
- アップロードをスキップして既存アセットにひもづけ:アップロードをスキップして、既存のアセットにひもづけます
- 既存アセットを上書きアップロード:アップロードして、既存アセットを上書きします
- アセットをリネームしてアップロード:リネームして既存アセットとは異なるアセットとしてアップロードし。コンテンツデータとひもづけます
このオプションはアセット単位に適用されるので、たとえば、
aaa.jpg
bbb.jpg
ccc.jpg
の3つの画像をZIPでインポートする場合、bbb.jpgという画像がすでに存在すれば、bbb.jpgにのみオプションが適用され、aaa.jpgとccc.jpgは自然体でアップロードとアセット登録およびアセットフィールドとのひもづけが行われます。
注:サーバ環境やアセット数・合計サイズによって正常にインポートできない可能性があります。
4.オプション
サイト別プラグイン設定画面に「ZIP形式でアセットをインポートする場合のルートパス」を追加しました。
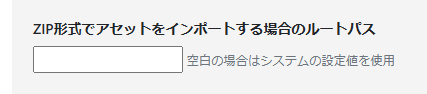
サイトパス直下にアップロードするようにしますが、assetsやimagesなど共通のパスが存在する場合、必要に応じて本項目を設定してください(デフォルト:設定なし)。
また、アップロードしたZIPファイル(/tmp上の一時ファイル)はインポート終了辞に削除する処理を追加しましたが、デバグ用として、一時ファイルを残すオプションをシステム管理画面に追加しました。

5-1.ユースケース1:CSVによる運用
これまでのコンテンツデータのアセットフィールドと、アセットファイルのひもづけは、
①サーバに画像をアップロード(MT機能や他のプラグイン利用)
②CSVファイルにファイルのフルパスを記入
③CSVファイルをインポート
という手順で実施が必要でしたが、
①ユーザーがローカルPCに画像を配置
②CSVファイルにファイルのパスを記入
③ZIPファイルをインポート
という手順で作業を行えるため、サーバーのアップロード作業を個別に行う手間がなくなります。
5-2.ユースケース2:画像の差し替え
任意のコンテンツデータのアセットの差し替えは、該当のコンテンツデータをエクスポートして、ASSET_DIR内の画像を置き替えてZIPを再作成し、インポートのオプションで「既存アセットを上書きアップロード」を選択・実行すれば差し替えが可能です。
5-3.ユースケース3:ホームページの引っ越し
通所のCSVエクスポート→インポートではアセットIDでひきつがれてしまうため、アセットの再ひもづけが大変ですが、アセット込みでエクスポート→インポートを実施すれば、アセットのひもづけを考える必要がなくなります。
6.プラグインについて
CSVDataImExporterプラグインの詳細は下記のページよりご覧いただけます。
確認用サイトもご用意しておりますので、試用をご希望される方はお問い合わせのページよりお申し込みください。
MT-9.0.2で追加された機能(更新履歴表示)
MT-9.0.2で追加された機能の紹介です。
更新履歴表示が変更されました(今後のバージョンアップで変更されるかもしれません)。
1.これまでの動作
「更新履歴を表示」をクリック。
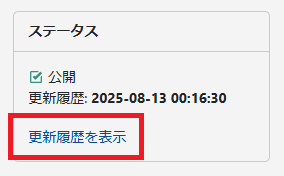
「下書き」のリンクをクリック。
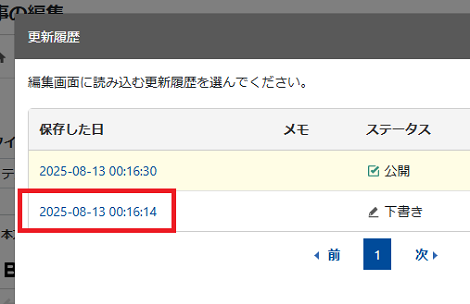
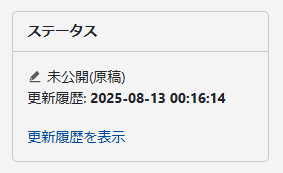
ステータスフィールドの表示が選択したリビジョンに切り替わります。
2.MT9(9.0.2)での動作
「更新履歴を表示」をクリック。
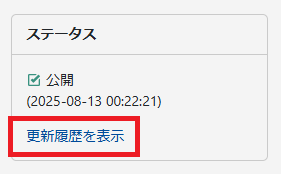
「下書き」のリンクをクリック。
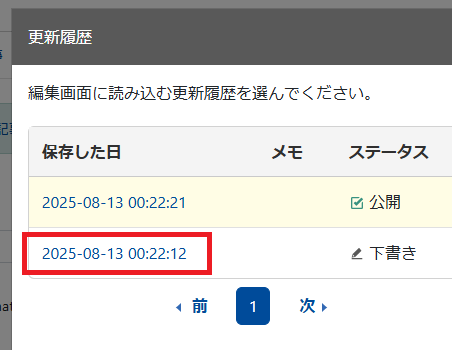
「最新」と「表示中」の2つのリビジョンが表示されます。
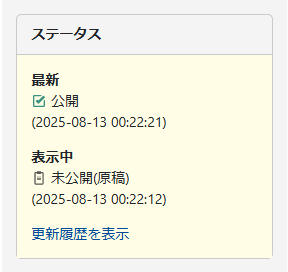
「最新」は文字通り、最新リビジョンのステータスとそのタイムスタンプです。
「表示中」は管理画面に表示されたリビジョンのステータスとそのタイムスタンプです。
更新履歴から最新以外のリビジョンを選択するとこの画面になるようです。
3.管理画面テンプレートの変更
開発者向け情報ですが、これまでステータスフィールドの表示は
MT_PATH/tmpl/admin2023/cms/include/status_widget.tmplで行われてましたが、今回の機能追加で、
MT_PATH/tmpl/admin2025/cms/include/status_label.tmplに変更されました(status_widget.tmplからインクルード)。
AWSのec2インスタンスにphpMyAdminをインストールする
AWSのec2インスタンスにphpMyAdminをインストールする手順を紹介します。
1.phpMyAdminのダウンロード
Amazon Linuxの標準リポジトリにphpMyAdminパッケージが含まれていないため、Amazon Linux 2023(amzn2023)では「dnf install phpMyAdmin」は使えません。
よって下記の手順でphpmyadminのアーカイブをダウンロードおよび展開します。
$ cd /var/www/html
$ sudo curl -L https://www.phpmyadmin.net/downloads/phpMyAdmin-latest-all-languages.tar.gz -o phpmyadmin.tar.gz
$ sudo tar xzf phpmyadmin.tar.gz
$ sudo mv phpMyAdmin-*-all-languages phpmyadmin
$ sudo rm phpmyadmin.tar.gz2.config.inc.phpの修正
、 phpMyAdminのconfig.inc.phpに以下を追加します。$cfg['blowfish_secret'] = '';
↓
$cfg['blowfish_secret'] = 'ランダム文字列(32文字以上がおすすめ)';ランダムな文字列は、
$ openssl rand -base64 32で作れます。
3.httpd.confの修正
この段階で試しにブラウザからアクセスしましたが、
Not Found
The requested URL was not found on this server.というエラーになったため、下記を実施(chownは不要かもしれません)。
$ sudo chown -R apache:apache /var/www/html/phpmyadmin
$ sudo vi /etc/httpd/conf/httpd.conf■変更前
<IfModule dir_module>
DirectoryIndex index.html
</IfModule>■変更後
<IfModule dir_module>
DirectoryIndex index.php index.html
</IfModule>
Alias /phpmyadmin /var/www/html/phpmyadmin
<Directory /var/www/html/phpmyadmin>
Options Indexes FollowSymLinks
AllowOverride All
Require all granted
</Directory>このあとhttpdを再起動します。
$ sudo systemctl restart httpd4.php.iniの修正
ここまでの設定で404は出なくなりましたが、
phpMyAdmin - Error
Error during session start; please check your PHP and/or webserver log file and configure your PHP installation properly. Also ensure that cookies are enabled in your browser.
session_start(): open(SESSION_FILE, O_RDWR) failed: No such file or directory (2)
session_start(): Failed to read session data: files (path: )というエラーが表示されるようになりました。調べると、
session.save_path
に値が設定されていないのが原因のようで、下記のコマンド、
$ php -i | grep session.save_path
session.save_path => no value => no valueで「no value」となるのが問題のようです。
session.save_pathはphp_info()でも確認できます。
これについては、
$ sudo vi /etc/php.iniで、ファイルを開いて、下記のSessionグループを追加。
[Session]
session.save_path = "/tmp"これで再度httpdを再起動します。
$ sudo systemctl restart httpdこれで修正が反映されない場合は、ec2インスタンスを再起動してみてください。
私の場合、ec23インスタンス再起動で設定が反映され、いつものphpMyAdminログイン画面が表示されました。

