Movable Typeで2つの環境のコンテンツデータ差分をチェックする「StageProdContentDiffプラグイン」
Category:[コンテンツデータ]
Tag:[MovableType, Plugin, StageProdContentDiff]
Permalink
Movable Typeで2つの環境のコンテンツデータ差分をチェックする「StageProdContentDiffプラグイン」を作ってみました。
これは「Movable Type Advent Calendar 2025」の24日目の記事です。
1.はじめに
先日の「MTDDC 2025」ではCSVDataImExporterを使って、本番環境とステージング環境でコンテンツデータおよびそれに紐づくアイテムの差分を解消する方法を紹介しました。
ただ、差分をみつける方法は人手に頼っている状態なので、その作業自体もある程度自動化できないかと考え、プラグインを作ってみました。
かなり雑な仕上がりなのでご容赦ください。
2.機能
Movable Typeの2つの環境(A、B)に投稿されたコンテンツデータを比較し、差分を出力します。
今回はプロトタイプということで、データ識別ラベルの有無のみチェックしています。
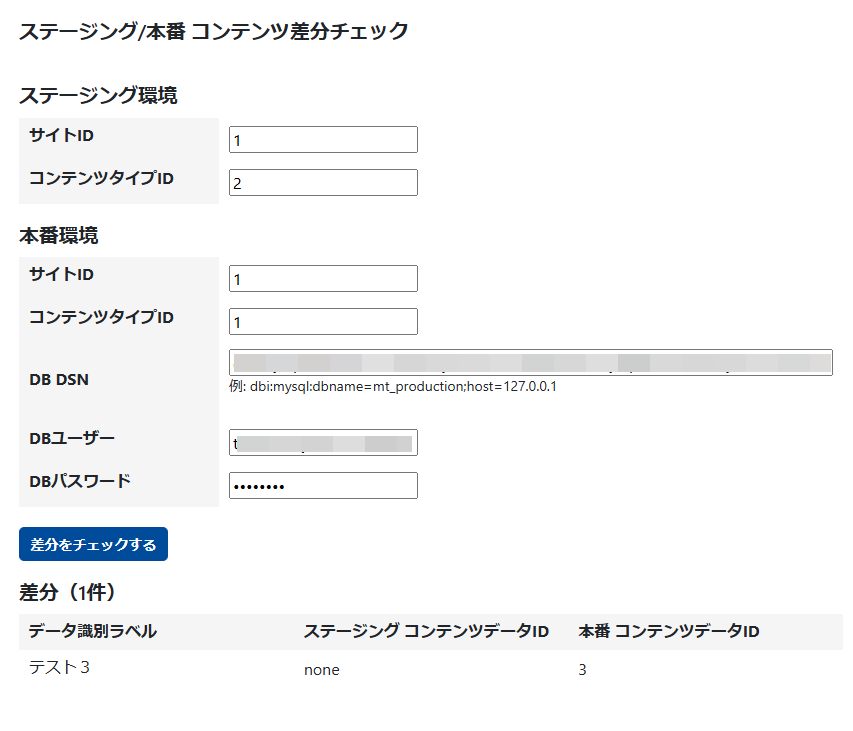
たとえば、環境A(本番)で、
- テスト1
- テスト2
- テスト3
環境B(ステージング)で、
- テスト1
- テスト2
というデータ識別ラベルのコンテンツデータが投稿されている場合、「テスト3」とそのIDを出力します。
MT8用です。
3.プラグインのダウンロード
プラグインは下記のURLからダウンロードできます。
4.使い方
ダウンロードしたアーカイブを展開して、plugins配下の「StageProdContentDiff」フォルダをMTのpluginsディレクトリにアップロードします。
比較したいサイトの管理画面メニューの「ツール」→「ステージング/本番 コンテンツ差分チェック」をクリック。
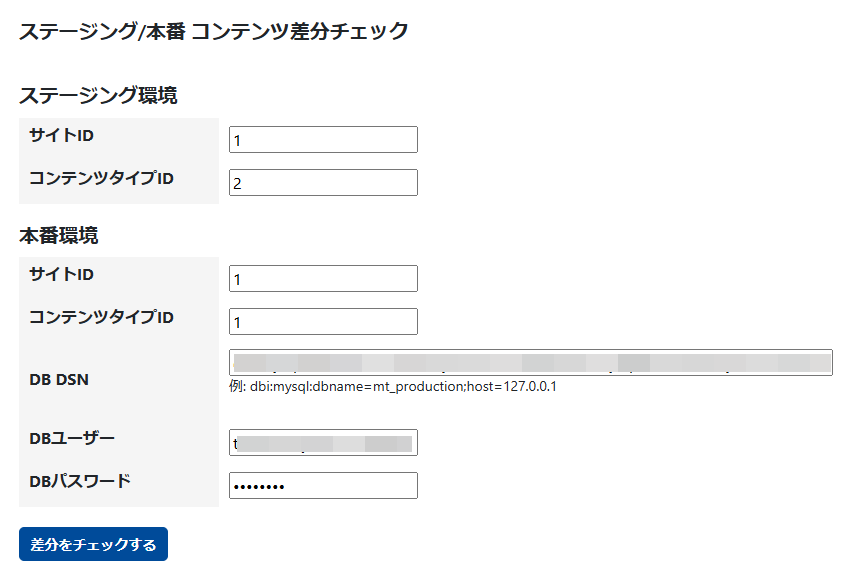
表示された画面で必要な項目を入力します。
ステージング環境
- サイトID
- コンテンツタイプID
本番環境
- サイトID
- コンテンツタイプID
- DB DSN
- DBユーザー
- DBパスワード
(クリックで拡大)
入力後、「差分をチェックする」をクリックすれば差分チェックが開始します。
上記の例では、次のような結果が表示されます。
(クリックで拡大)
4.今後の予定
コンテンツデータの各コンテンツフィールドの差分もチェックする機能など追加する予定です。
CSVDataImExporterプラグイン(CLI版)
CSVDataImExporterプラグイン(CLI版)をリリースしました。
1.概要
ブラウザでのエクスポート・インポートのほぼすべての操作をCLIで制御することが可能です。
また、先日リリースした、記事・コンテンツデータのアセットフィールドに紐づいているアセット(画像・オーディオ・ビデオ・ファイル)をCSVファイルとペアでダウンロードすることも可能です。
2.エクスポート機能
export_csvというツールを提供します。
このツールを
3.インポート機能
import_csvというツールを提供します。
このツールを
4.その他
オプション等の詳細についてはお問い合わせください。
5.開発の背景
ブラウザ経由で大量のデータをインポートあるいはエクスポートすると、サーバ環境要因等で処理が最後まで正常に処理されない可能性があり、今回のCLIによるソリューション開発に至りました。
たとえば、cronでインポートツールを登録しておけば、大量のCSVデータを深夜にインポートすることも可能です。
6.プラグインについて
CSVDataImExporterプラグインの詳細は下記のページよりご覧いただけます。
確認用サイトもご用意しておりますので、試用をご希望される方はお問い合わせのページよりお申し込みください。
「MTDDC Meetup Tokyo 2025」の発表スライド
2025年11月29日、「MTDDC Meetup Tokyo 2025」が開催され、昨年に続き登壇させて頂きました。
今回は「まだまだ進化するCSVプラグイン」というタイトルでお話ししました。
内容は、当ブログでリリースしているCSVDataImExporterの機能についての説明で、これまでの機能の紹介と、新たに追加した機能の紹介です。
特に、先日リリースしたアセットアップロードとCLI機能を追加したことで、より多くのシチュエーションに対応できるようになったと思います。
実際のデモも行いましたが、登壇10分前にPC内で起動していたVMwareがメモリ不足でクラッシュしてしまい、登壇終了間際にデモ用のターミナルを準備をするという、今年一番焦った出来事でした。
ということで、そのときの発表スライド(PDF)を公開しておきます。
MovableType 9リリースと当ブログのプラグイン対応状況
MovableType 9が2025年10月22日にリリースされました。
シックスアパートのみなさま、リリース作業おつかれさまでした!
ということで、小粋空間でリリース中のプラグイン対応状況です(MT-9.0.4で動作確認済)。
対応済のプラグイン
- CSVDataImExpoter
- ListingFieldEditor
- PowerEditContentData
- PowerListingFieldEditor
- PublishDraft
- Trash
- Vote ※
- Workflow
※mt-data-api.js の同梱が終了したため、引き続き使用する場合は、
https://github.com/movabletype/mt-data-api-sdk-js/tree/master/mt-static/data-api
からのダウンロードおよび設定が必要です。
対応予定のプラグイン
- CSVAssetDataImExporter
- CSVAuthorDataImExporter
- EntryConverter
- SaveWithoutRebuild
詳細は、各プラグインの販売ページでお知らせしていく予定ですので、お待ちください。
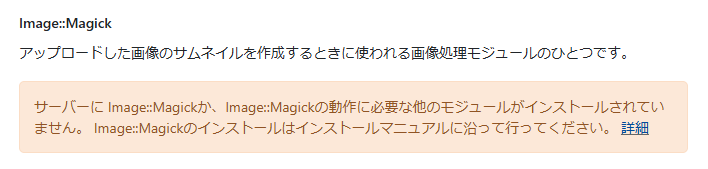
CentOS Stream release 9にImageMagickとPerlMagickをインストール
CentOS Stream release 9にImageMagickとPerlMagickをインストールしてみました。
1.はじめに
ある環境のMovable Type 8でImageMagickが使えない状態(下)であったため、インストールしてみました。
調べたところ、dnf(旧yum)などでは期待する環境が作れないようなので、ソースからビルドしました。
2、ソースコード取得
ImageMagickの公式サイトより、tar.gzファイルをダウンロードします。
https://imagemagick.org/archive/
バージョンが合わない場合は下記より該当のバージョンを選択します。
https://imagemagick.org/archive/releases/
私の環境でdnfでinstallしたときのバージョンが「ImageMagick-6.9.13.25-1.el9.x86_64」だったので、同じバージョンの
ImageMagick-6.9.13.25-1.el9.x86_64.tar.gz
をダウンロード。
dnfでインストールしたImageMagickは
# dnf history
# dnf history undo xxで一旦削除しました。
undoする番号はdnf historyで表示されます。
# dnf history
ID | コマンドライン | 日時 | 動作 | 変更さ
-------------------------------------------------------------------------------------------------------------------
15 | install perl-ExtUtils-MakeMaker ImageMagick ImageMagick-devel | 2025-10-18 00:39 | Install | 1
14 | install ImageMagick | 2025-10-18 00:34 | Install | 17
# dnf history undo 15
略
# dnf history undo 14
略
3.ビルドに必要なパッケージのインストール
# dnf install -y gcc-c++ make pkgconfig \
libjpeg-devel libpng-devel libtiff-devel freetype-devel \
lcms2-devel libwebp-devel libxml2-devel bzip2-devel \
perl-ExtUtils-MakeMaker4.アーカイブを展開して、ディレクトリに移動
# tar xvf ImageMagick-6.9.13-25.tar.xz
# cd ImageMagick-6.9.13-25/5.コンフィグ作成
最初、下記のオプションで実施したところ、
./configure \
--prefix=/usr/local/imagemagick \
--enable-shared \
--with-modules \
--with-perlconfigure: error: in '/usr/local/src/ImageMagick-6.9.13-25':
configure: error: libltdl is required for modules and OpenCL buildsというエラーが発生して、
# dnf install libtool-ltdl-develを実施したのですが、
引数に一致する結果がありません: libtool-ltdl-devel
エラー: 一致するものが見つかりません: libtool-ltdl-develということで、"--disable-opencl"オプションを追加したところ、成功しました。
# ./configure \
--prefix=/usr/local/imagemagick \
--enable-shared \
--without-modules \
--disable-opencl \
--with-perlちなみに"--with-perl"を付与することでPerlMagickもビルド対象になります(アーカイブの中にあるPerlMagickというディレクトリがそれです)。
6.コンパイルとインストール
あとは、
# make
# make install
# ldconfig /usr/local/imagemagick/libを実施しました。
7.PerlMagickの確認
$ perl -MImage::Magick -e 'print "OK\n"'
OKと表示されればOKです。
これでMTからもImage::Magickが使えるようになりました。

AWS EC2にMovable Type(AMI版)をインストールする方法
AWS EC2にMovable Type(AMI版)をインストールする方法を紹介します。
AWSのアカウント作成やログインは省略しています。
1.EC2インスタンス作成
サービス→「EC2」をクリック。
「インスタンスを起動」をクリック。
「その他のAMIを閲覧する」をクリック。
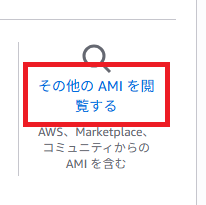
movableypeを入力。
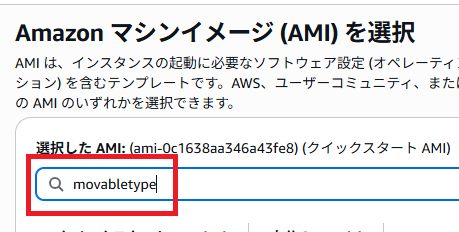
「AWS Marketplace AMI」タブをクリック。
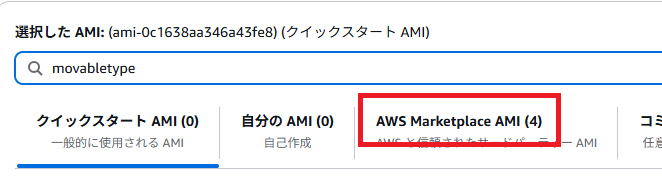
「Movable Type 8.4 (Amazon Linux 2023, x86_64)」をクリック(2025年5月時点の最新版)。
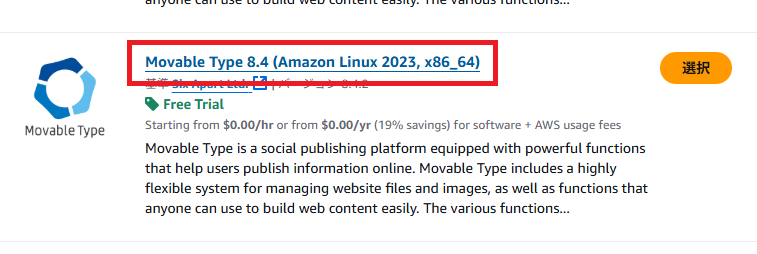
「今すぐ購読」をクリック。インスタンスタイプはこの後選択できます。

インスタンスタイプから「t2.micro」を選択。
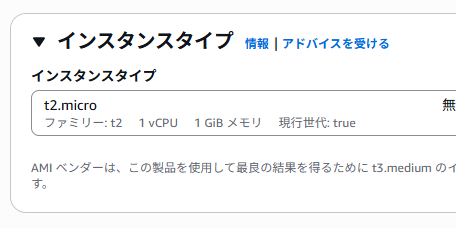
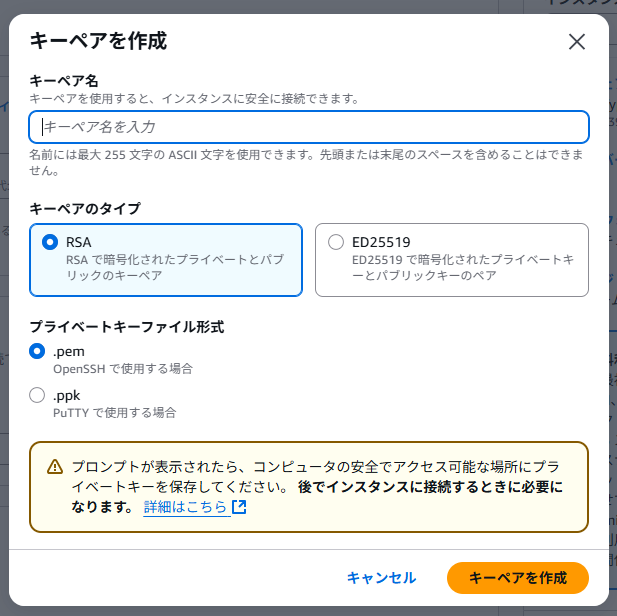
キーペアで「新しいキーペアの作成」をクリック。

キーペア名に任意の名称を入力して、「キーペアを作成」をクリック。クリックすると鍵のダウンロード画面になるので、任意のフォルダに保存。
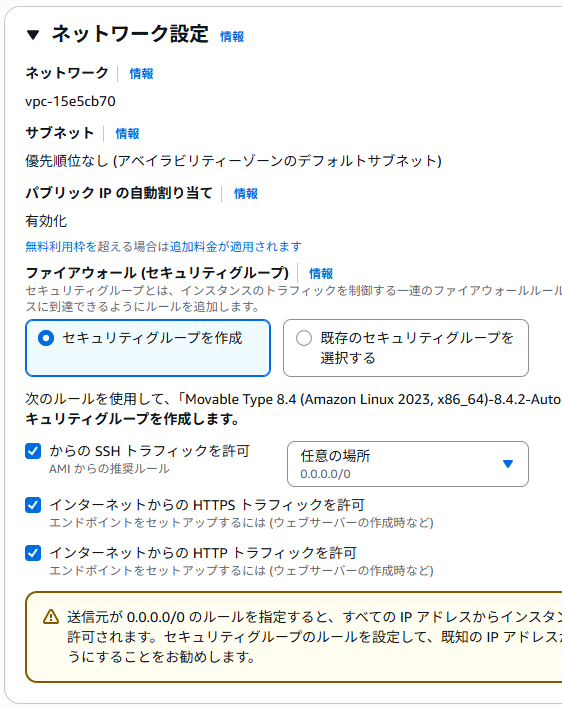
ネットワーク設定は、デフォルトの状態とします。
ストレージもデフォルトのままとします。
一番上のタグに任意の名称を設定。
「インスタンスを起動」をクリック。
インスタンスが起動されます。
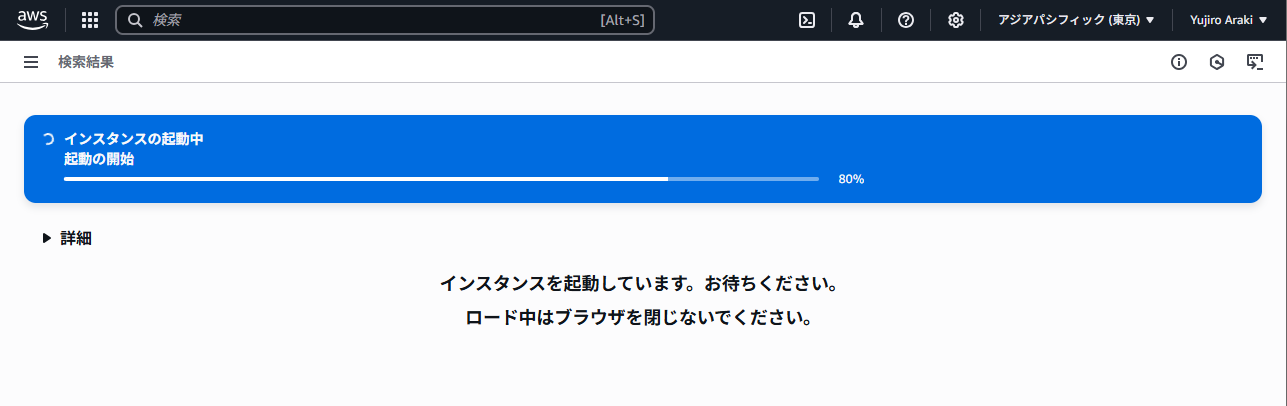
「インスタンスに接続」をクリック。

右下の「接続」をクリック。
インスタンスIDを入力して「Continue」をクリック。
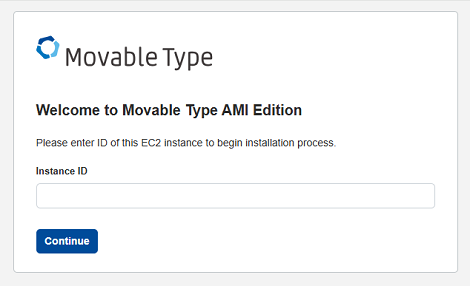
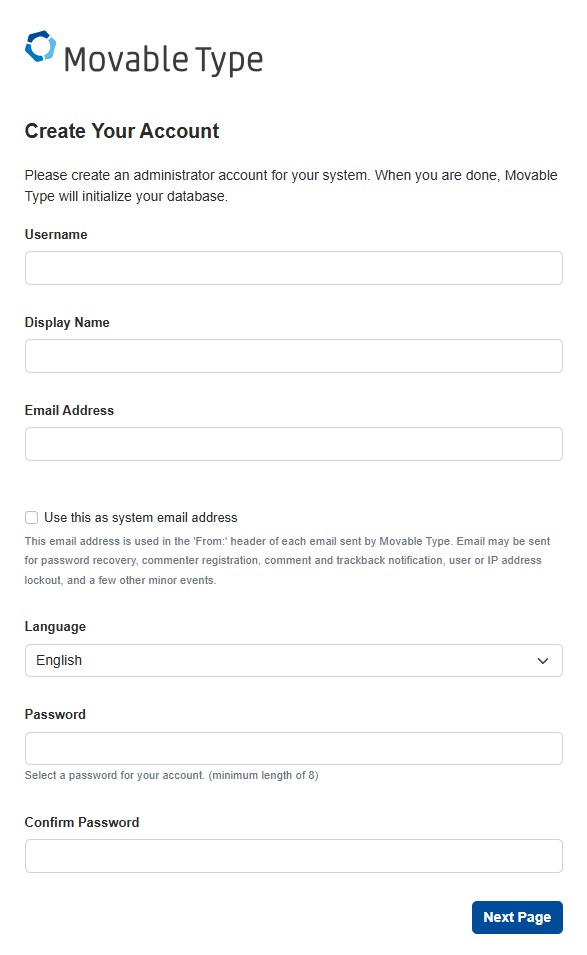
これでいつものインストール画面が表示されます。
なお、インスタンスを普段使用しないのであれば、インスタンスは停止しておきましょう。
CSVDataImExporterプラグイン(アセットアップロード・ダウンロード対応版)
CSVDataImExporterプラグイン(アセットアップロード・ダウンロード対応版)をリリースしました。
1.概要
コンテンツデータのアセットフィールドに紐づいているアセット(画像・オーディオ・ビデオ・ファイル)をCSVファイルとペアでダウンロードすることが可能です。
また、CSVのインポート時にアセットをあわせてアップロード(ZIP形式)することで、アセットの登録と、CSVのコンテンツデータのアセットフィールドとの関連づけが同時に行えます。
注:2025年9月現在、記事アセットおよびカスタムフィールドに対しての機能追加はありません。
2-1.エクスポート機能(コンテンツデータ一覧画面)
コンテンツデータ一覧画面の「アクション」に「 コンテンツデータのエクスポート・アセットダウンロードつき(ZIP) 」というメニューを追加しました。
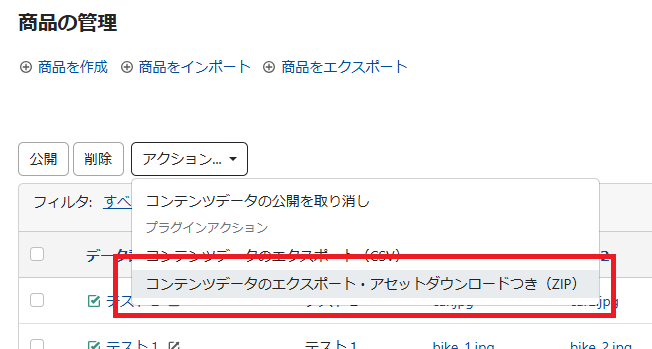
この項目を選択してCSVをエクスポートすると、ZIP形式でのダウンロードとなり、ZIPファイルの内容は次のようになります。
export-001-002-20250816152706.zip
├─ export-001-002-20250816152706.csv ← CSVファイル
└─ ASSET_DIR/ ← アセット格納用フォルダ
├─ assets/
│ └─ 2025/
│ └─ 09/
│ ├─ file1.jpg
│ └─ file2.jpg
├─ images/
│ └─ file2.webp
└─ s-l960.pdfまた、CSVのアセットフィールドには、下記のように「パス+ファイル名」で設定されます(赤字部分)。
content_type,id,label,author_id,identifier,authored_on,modified_on,unpublished_on,status,名前,画像1,画像2
商品,1,テスト1,1,2b909dd37403b295ff80f6f46d23fd72cebf41d5,2025/8/6 0:58,2025/8/22 23:06,,2,テスト1,assets/2025/09/file1.jpg,s-l960.pdf
商品,2,テスト2,1,f46d23fd72cebf41d5295ff80f6f4609dd37403b,2025/8/6 0:58,2025/8/22 23:06,,2,テスト2,assets/2025/09/file2.jpg,images/file2.webp2-2.エクスポート機能(エクスポート画面)
エクスポート画面にも「アセットダウンロードつき(ZIP) 」というメニューを追加しました。

チェックすればすべてのコンテンツデータにひもづくアセットをダウンロードします。
注:サーバ環境やアセット数・合計サイズによって正常にエクスポートできない可能性があります。
3.インポート機能
インポート画面に「ZIPファイルのアセット 」というメニューを追加しました。

基本動作は、ZIPファイルを指定してインポートすれば、CSVのアセットフィールドに記載されたパス・ファイル内を使って、ZIPのASSET_DIR配下に存在するアセットをアップロードしながら、コンテンツデータのアセットフィールドとひもづけていきます。
そのため、すでに同一パス・ファイルのアセットがサイトに存在する場合の挙動を追加したメニューで指定します。
- アップロードをスキップして既存アセットにひもづけ:アップロードをスキップして、既存のアセットにひもづけます
- 既存アセットを上書きアップロード:アップロードして、既存アセットを上書きします
- アセットをリネームしてアップロード:リネームして既存アセットとは異なるアセットとしてアップロードし。コンテンツデータとひもづけます
このオプションはアセット単位に適用されるので、たとえば、
aaa.jpg
bbb.jpg
ccc.jpg
の3つの画像をZIPでインポートする場合、bbb.jpgという画像がすでに存在すれば、bbb.jpgにのみオプションが適用され、aaa.jpgとccc.jpgは自然体でアップロードとアセット登録およびアセットフィールドとのひもづけが行われます。
注:サーバ環境やアセット数・合計サイズによって正常にインポートできない可能性があります。
4.オプション
サイト別プラグイン設定画面に「ZIP形式でアセットをインポートする場合のルートパス」を追加しました。
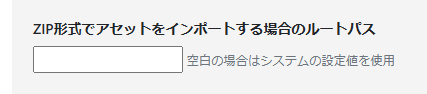
サイトパス直下にアップロードするようにしますが、assetsやimagesなど共通のパスが存在する場合、必要に応じて本項目を設定してください(デフォルト:設定なし)。
また、アップロードしたZIPファイル(/tmp上の一時ファイル)はインポート終了辞に削除する処理を追加しましたが、デバグ用として、一時ファイルを残すオプションをシステム管理画面に追加しました。

5-1.ユースケース1:CSVによる運用
これまでのコンテンツデータのアセットフィールドと、アセットファイルのひもづけは、
①サーバに画像をアップロード(MT機能や他のプラグイン利用)
②CSVファイルにファイルのフルパスを記入
③CSVファイルをインポート
という手順で実施が必要でしたが、
①ユーザーがローカルPCに画像を配置
②CSVファイルにファイルのパスを記入
③ZIPファイルをインポート
という手順で作業を行えるため、サーバーのアップロード作業を個別に行う手間がなくなります。
5-2.ユースケース2:画像の差し替え
任意のコンテンツデータのアセットの差し替えは、該当のコンテンツデータをエクスポートして、ASSET_DIR内の画像を置き替えてZIPを再作成し、インポートのオプションで「既存アセットを上書きアップロード」を選択・実行すれば差し替えが可能です。
5-3.ユースケース3:ホームページの引っ越し
通所のCSVエクスポート→インポートではアセットIDでひきつがれてしまうため、アセットの再ひもづけが大変ですが、アセット込みでエクスポート→インポートを実施すれば、アセットのひもづけを考える必要がなくなります。
6.プラグインについて
CSVDataImExporterプラグインの詳細は下記のページよりご覧いただけます。
確認用サイトもご用意しておりますので、試用をご希望される方はお問い合わせのページよりお申し込みください。
MT-9.0.2で追加された機能(更新履歴表示)
MT-9.0.2で追加された機能の紹介です。
更新履歴表示が変更されました(今後のバージョンアップで変更されるかもしれません)。
1.これまでの動作
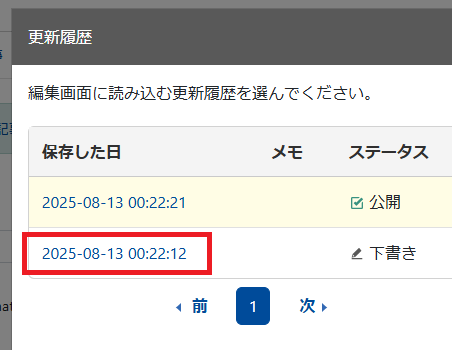
「更新履歴を表示」をクリック。
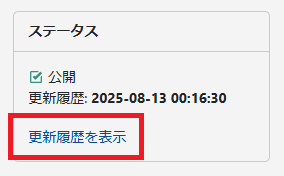
「下書き」のリンクをクリック。
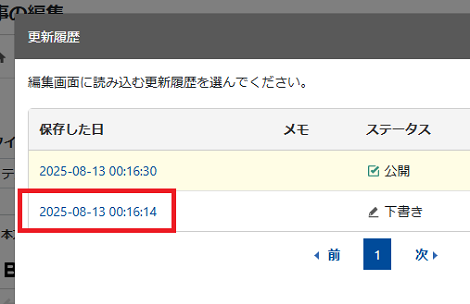
ステータスフィールドの表示が選択したリビジョンに切り替わります。
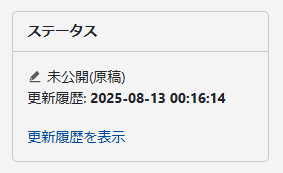
2.MT9(9.0.2)での動作
「更新履歴を表示」をクリック。
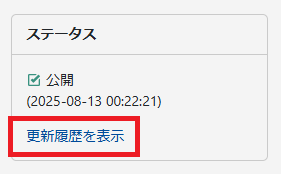
「下書き」のリンクをクリック。
「最新」と「表示中」の2つのリビジョンが表示されます。
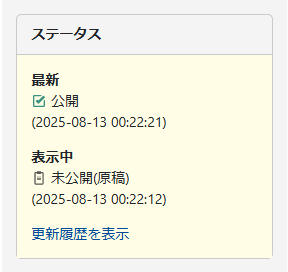
「最新」は文字通り、最新リビジョンのステータスとそのタイムスタンプです。
「表示中」は管理画面に表示されたリビジョンのステータスとそのタイムスタンプです。
更新履歴から最新以外のリビジョンを選択するとこの画面になるようです。
3.管理画面テンプレートの変更
開発者向け情報ですが、これまでステータスフィールドの表示は
MT_PATH/tmpl/admin2023/cms/include/status_widget.tmplで行われてましたが、今回の機能追加で、
MT_PATH/tmpl/admin2025/cms/include/status_label.tmplに変更されました(status_widget.tmplからインクルード)。
AWSのec2インスタンスにphpMyAdminをインストールする
AWSのec2インスタンスにphpMyAdminをインストールする手順を紹介します。
1.phpMyAdminのダウンロード
Amazon Linuxの標準リポジトリにphpMyAdminパッケージが含まれていないため、Amazon Linux 2023(amzn2023)では「dnf install phpMyAdmin」は使えません。
よって下記の手順でphpmyadminのアーカイブをダウンロードおよび展開します。
$ cd /var/www/html
$ sudo curl -L https://www.phpmyadmin.net/downloads/phpMyAdmin-latest-all-languages.tar.gz -o phpmyadmin.tar.gz
$ sudo tar xzf phpmyadmin.tar.gz
$ sudo mv phpMyAdmin-*-all-languages phpmyadmin
$ sudo rm phpmyadmin.tar.gz2.config.inc.phpの修正
、 phpMyAdminのconfig.inc.phpに以下を追加します。$cfg['blowfish_secret'] = '';
↓
$cfg['blowfish_secret'] = 'ランダム文字列(32文字以上がおすすめ)';ランダムな文字列は、
$ openssl rand -base64 32で作れます。
3.httpd.confの修正
この段階で試しにブラウザからアクセスしましたが、
Not Found
The requested URL was not found on this server.というエラーになったため、下記を実施(chownは不要かもしれません)。
$ sudo chown -R apache:apache /var/www/html/phpmyadmin
$ sudo vi /etc/httpd/conf/httpd.conf■変更前
<IfModule dir_module>
DirectoryIndex index.html
</IfModule>■変更後
<IfModule dir_module>
DirectoryIndex index.php index.html
</IfModule>
Alias /phpmyadmin /var/www/html/phpmyadmin
<Directory /var/www/html/phpmyadmin>
Options Indexes FollowSymLinks
AllowOverride All
Require all granted
</Directory>このあとhttpdを再起動します。
$ sudo systemctl restart httpd4.php.iniの修正
ここまでの設定で404は出なくなりましたが、
phpMyAdmin - Error
Error during session start; please check your PHP and/or webserver log file and configure your PHP installation properly. Also ensure that cookies are enabled in your browser.
session_start(): open(SESSION_FILE, O_RDWR) failed: No such file or directory (2)
session_start(): Failed to read session data: files (path: )というエラーが表示されるようになりました。調べると、
session.save_path
に値が設定されていないのが原因のようで、下記のコマンド、
$ php -i | grep session.save_path
session.save_path => no value => no valueで「no value」となるのが問題のようです。
session.save_pathはphp_info()でも確認できます。
これについては、
$ sudo vi /etc/php.iniで、ファイルを開いて、下記のSessionグループを追加。
[Session]
session.save_path = "/tmp"これで再度httpdを再起動します。
$ sudo systemctl restart httpdこれで修正が反映されない場合は、ec2インスタンスを再起動してみてください。
私の場合、ec23インスタンス再起動で設定が反映され、いつものphpMyAdminログイン画面が表示されました。
WindowsでRGB画像をCMYK画像に変換する方法
WindowsでRGB画像をCMYK画像に変換する方法を紹介します。
1.はじめに
GIMPを使って画像を加工していたのですが、加工した画像がRGBカラーでした。
GIMPではRGBからCMYKに変換することができないようです。
ということで、WindowsでRGB画像をCMYK画像に変換する方法を紹介します。
2.RGB画像をCMYK画像に変換する
RGB画像をCMYK画像に変換するには「KRITA(クリータ、クリタ)」という、オープンソースソフトウェアのペイントソフトを使用します。
インストール手順は省略します。
使用しているKRITAのバージョンは5.2.9です。
KRITAを起動し、CMYKに変換したい画像を「ファイル」→「開く」で開きます。
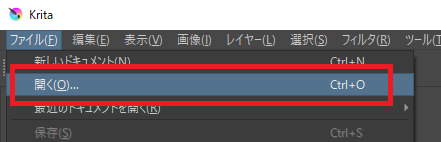
開くと下部に「RGB~」と表示されていると思います。
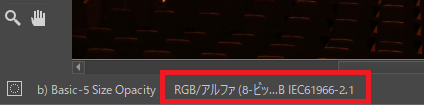
「画像」→「プロパティ」を選択。
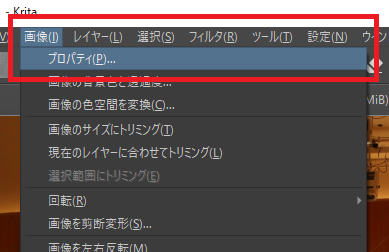
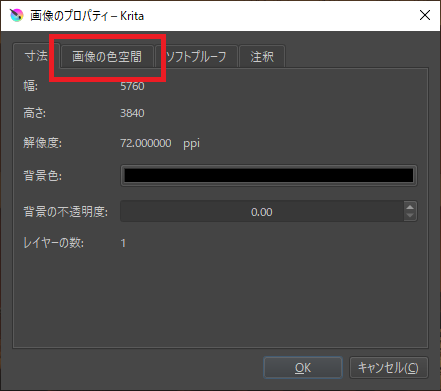
「画像の色空間」タブをクリック。
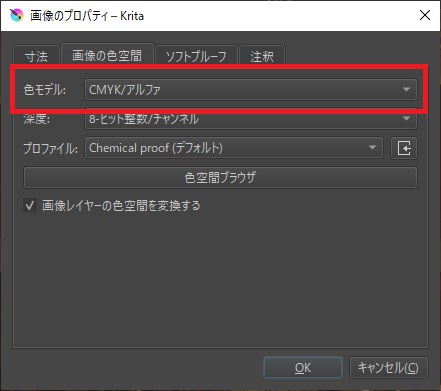
「色モデル」を「RGB~」から「CMYK~」に変更して「OK」をクリック。
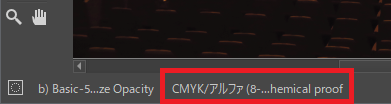
下部の表示が「CMYK~」に変わっていることを確認。
あとは「ファイル」→「保存」で上書きするか「名前をつけて保存」で別名で保存すれば完了です。
AWSでIAMユーザーを作成する方法
AWSでIAMユーザーを作成する方法を紹介します。
1.はじめに
AWSに久しぶりにアクセスしてみると、ログイン画面が「アカウントID」と「IAMユーザー」に変わっていました。
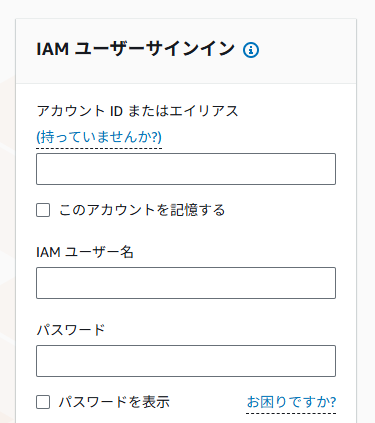
IAMユーザーというものをそもそも作っていなかったので、本記事で作成方法を紹介します。
なお、アカウントIDは後述するルートユーザーでログイン後、右上のユーザー名をクリックすれば「アカウントID」が表示されます。
2.AWSでIAMユーザーを作成する
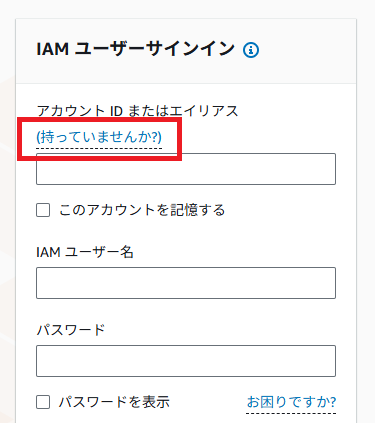
AWSマネジメントコンソールにアクセス。
「持っていませんか?」のリンクをクリックすればルートユーザーでログインできる画面に切り替わるので、ルートユーザーでログインします(詳細は省略)。
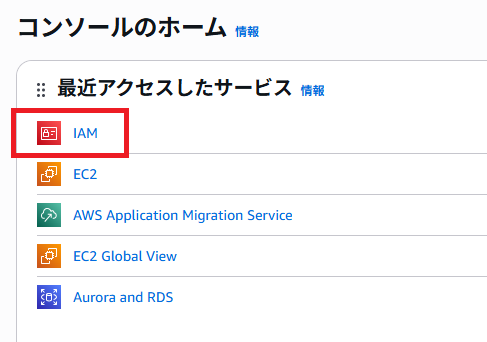
ログイン後、左上の「IAM」を選択
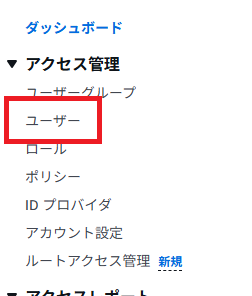
「ユーザー」をクリック。
「ユーザーの作成」をクリック。
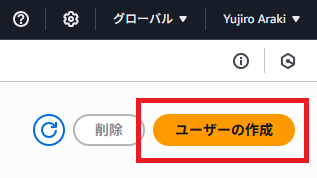
任意のユーザー名を設定して、「ユーザータイプ 」から「IAM ユーザーを作成します」を選択。パスワードの作成方法は任意。
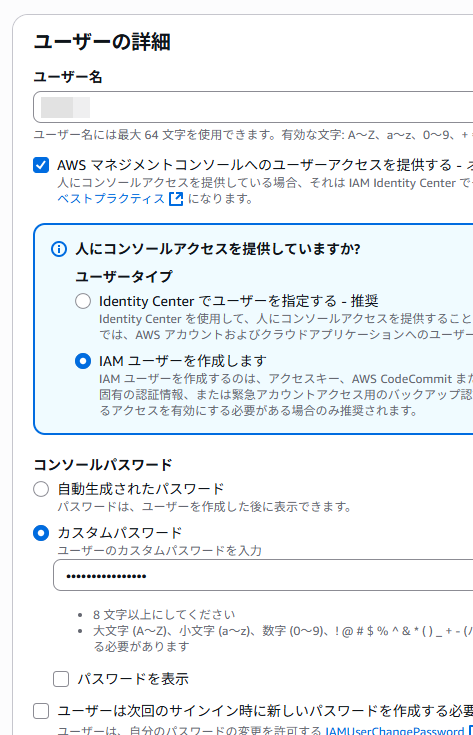
すべて設定後「次へ」をクリック。

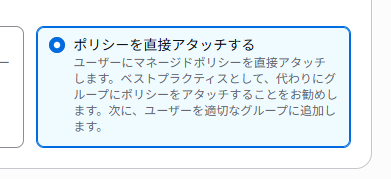
今回は1ユーザーで、ユーザーグループを作成しないので、「ポリシーを直接アタッチする」を選択。
作成するユーザーにすべての権限を与えたいので、「AdministratorAccess」のみをチェック。その下の「許可の境界を設定」はスキップします。
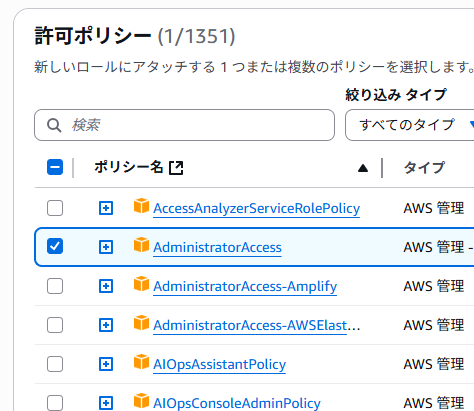
すべて設定後「次へ」をクリック。
設定した内容の確認画面が表示されるので、問題なければ「ユーザーの作成」をクリック。
「ユーザーが正常に作成されました」が表示されれば完了です。コンソールサインインURLやパスワードも表示されます。

なお、これまでルートユーザーで作成したものは、別ユーザーなので一切表示されないようです。
ansibleで同名のroleを複数回実行する方法
ansibleで同名のroleを複数回実行する方法を紹介します。
1.問題点
次のroleを作成しました。
roles/test/tasks/main.yml
- name: コマンド実行
shell:
cmd: hostname
register: result
- name: 結果出力
debug:
msg: "{{ result.stdout_lines }}"このroleを実行するplaybook(test.yml)は下記です。
- hosts: localhost
connection: local
roles:
- role: test
- role: test
- role: testinventoryは省略しますので適宜用意してください。
このplaybookを実行すると、roleは一度しか実行されません。
(ansible) [hoge@server ~]$ ansible-playbook -i inventory test.yml
PLAY [localhost] ********************************************************************************************************************
TASK [Gathering Facts] **************************************************************************************************************
ok: [localhost]
TASK [test : コマンド実行] **********************************************************************************************************
changed: [localhost]
TASK [test : 結果出力] **************************************************************************************************************
ok: [localhost] => {
"msg": [
"hoge-server"
]
}
PLAY RECAP **************************************************************************************************************************
localhost : ok=3 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=02.原因
これは、Ansibleが「ロールの重複適用」を避ける設計になっているためです。
3.対処
いくつか方法はあるようですが、ここではplaybook内で「tags」を付与する方法を紹介します。
下記のように、roleごとにtagsを追加して、ユニークな値を設定します。
test.yml
- hosts: localhost
connection: local
roles:
- role: test
tags: "1"
- role: test
tags: "2"
- role: test
tags: "3"これで同名のroleでも期待通り実行されます。
(ansible) [hoge@server ~]$ ansible-playbook -i inventory test.yml
PLAY [localhost] ********************************************************************************************************************
TASK [Gathering Facts] **************************************************************************************************************
ok: [localhost]
TASK [test : コマンド実行] **********************************************************************************************************
changed: [localhost]
TASK [test : 結果出力] **************************************************************************************************************
ok: [localhost] => {
"msg": [
"hoge-server"
]
}
TASK [test : コマンド実行] **********************************************************************************************************
changed: [localhost]
TASK [test : 結果出力] **************************************************************************************************************
ok: [localhost] => {
"msg": [
"hoge-server"
]
}
TASK [test : コマンド実行] **********************************************************************************************************
changed: [localhost]
TASK [test : 結果出力] **************************************************************************************************************
ok: [localhost] => {
"msg": [
"hoge-server"
]
}
PLAY RECAP **************************************************************************************************************************
localhost : ok=7 changed=3 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0Movable Type 9をインストールしてみた
Movable Type 9のデベロッパープレビューが公開されていたので、インストールしてみました。
Movable Type 9 デベロッパープレビュー を公開しました
ここではMT8との管理画面の違いを紹介します。
1.ダッシュボード
サイドバーがデフォルトで非表示になりました。
(クリックで拡大)
システム管理画面へのリンクがみつからなかったのですが、ヘッダー右上の歯車アイコンに移動したようです。
検索アイコンをクリックすると、検索フォームが表示されます。
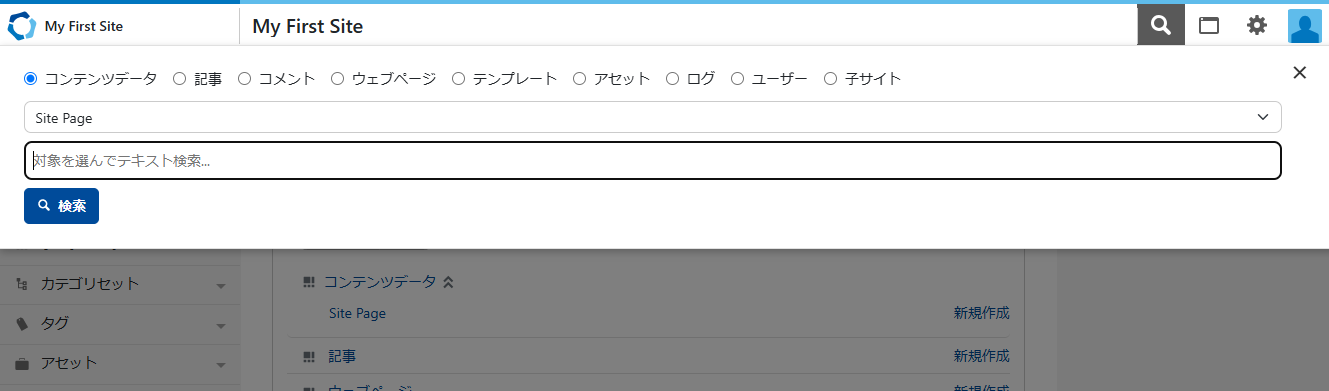
サイトアイコンをクリックすると、各サイトへのリンクが表示されます。
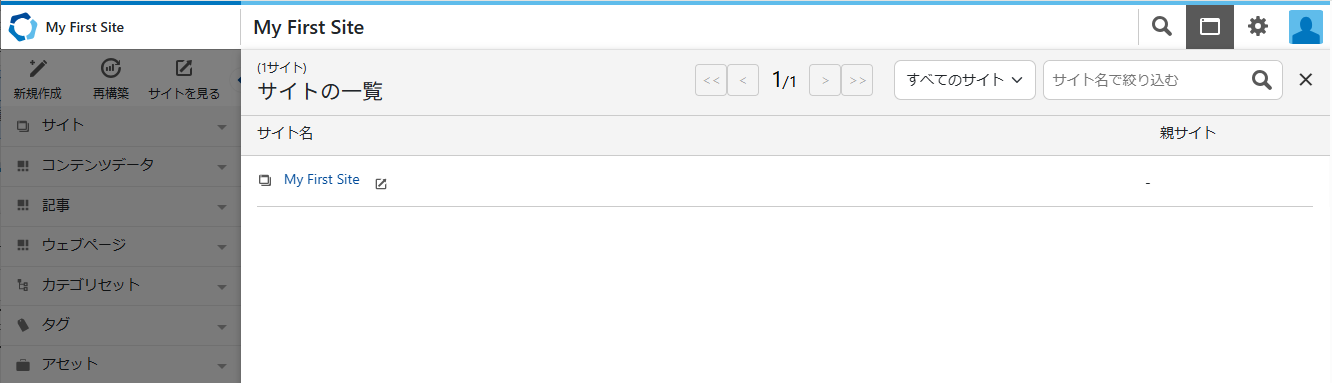
なお、このヘッダー部分はスクロールしても固定されているので、各メニュー共通になります。
2.サイト
サイト別管理画面でサイドバーが表示されます。
サイドバー上部にあった検索はヘッダーに移動し、「再構築」はそのまま、「サイトの表示」は「サイトを見る」に表記が変わり、「新規作成」が追加されました。
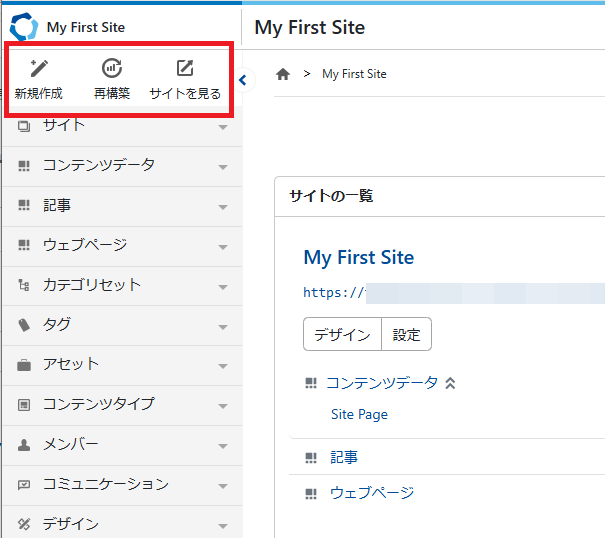
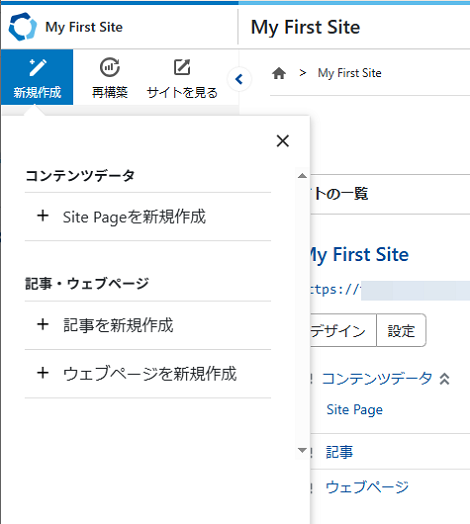
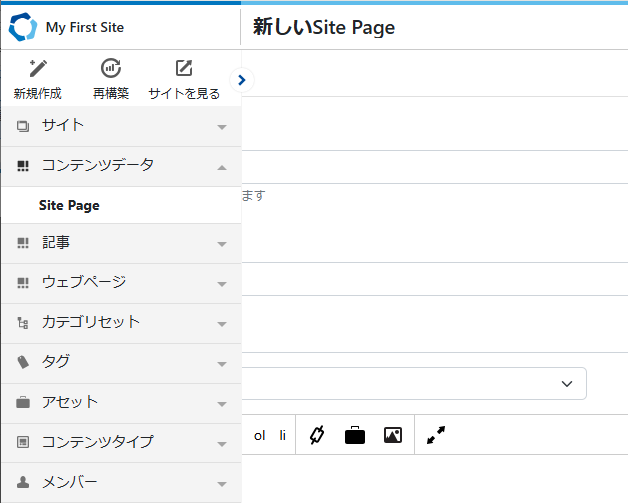
「新規作成」をクリックすると、コンテンツデータ・記事・ウェブページのサブメニューが表示されます。
赤枠のアイコンをクリックすると、サイドバーを折りたためます。
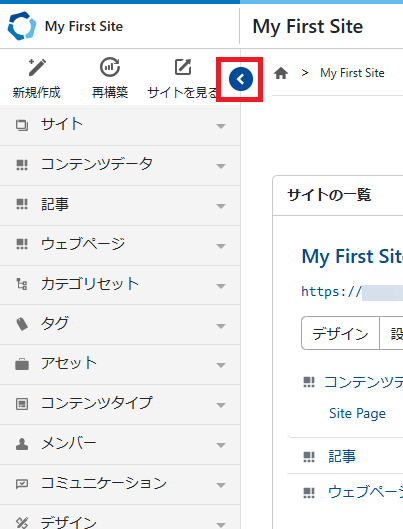
折りたたんだ状態です。
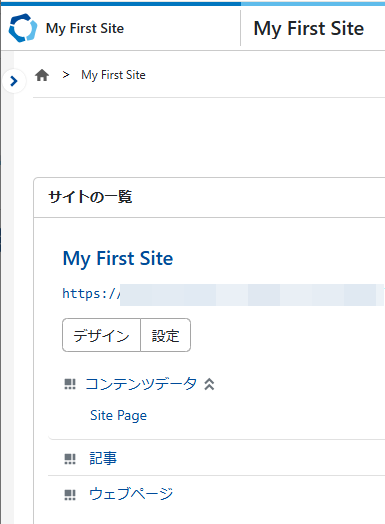
折りたたんだ状態でもサイドバー(矢印アイコン以外の部分)にマウスをポイントすると、一時的に表示されます。
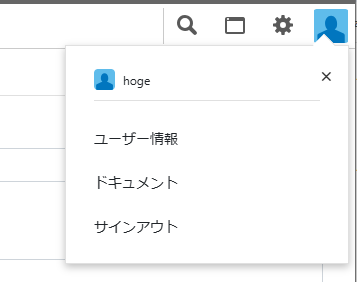
サイドバー株のユーザー名や「ユーザー情報」「ドキュメント」「サインアウト」はヘッダー右端に移動しました。
ダッシュボードに戻るには、左上のMTのアイコンか、パンくずリストの家のアイコンをクリックします。
以上です。
ansibleでハッシュの配列をチェックする方法
ansibleでハッシュの配列をチェックする方法を紹介します。
1.はじめに
下記の3ファイルのmd5sum値を予め用意したコンフィグに設定し、サーバ上の各ファイルのmd5sumと等しいか、チェックする必要が生じました。
ということで、ansibleでハッシュの配列をチェックする方法を紹介します。
2.やりたいこと
複数のファイルをチェックできるように、ファイル名とファイルのmd5sum値をハッシュの配列にしたいです。
ファイルのパスも動的に取得したいので、同じくハッシュの配列に含めます。
また、コンフィグはrolesディレクトリの中ではなく、分かりやすい任意の場所に配置したいです。
3.コンフィグのサンプル
前項の要望にしたがい、コンフィグは下記のようにしました。
/var/tmp/config.yml
files:
- name: kdump
path: /etc/sysconfig
md5sum: e417c7b5754df7287f41b478f2200793
- name: CentOS-Base.repo
path: /etc/yum.repos.d
md5sum: 447b4d2df1a36e64348bbd8b6c5b0fae
- name: sysctl.conf
path: /etc
md5sum: 4bae3962eeef7d1e7c7ef39314db9fb0"files"というハッシュキーの中に配列を作り、さらにそれぞれの配列に、
- ファイル名
- ファイルパス
- md5sum値
を設定しました。
これをansibleで読み込ませるにはどうすればいいかを次項で説明します。
4.コンフィグファイルの読み込み
コンフィグファイルを読み込むには、Playbook本体(test.yml)に"vars_files"を用います。
test.yml
- hosts: test
roles:
- role: test
vars_files:
- "/var/tmp/config.yml"これで、実行するロール内のタスクで前述のコンフィグを読み込むことができます。
5.ハッシュの配列をチェック
ハッシュの配列をチェックするには、ロール内のタスク(roles/test/tasks/main.yml)を下記のようにします。
roles/test/tasks/main.yml
- name: ファイルのmd5sum実行
command: "md5sum {{ item.path }}/{{ item.name }}"
loop: "{{ files }}"
register: file_md5_result
changed_when: false
- name: ファイルのmd5sum結果取得
set_fact:
md5sum_result: "{{ item.stdout.split(' ')[0] }}"
loop: "{{ file_md5_result.results }}"
register: file_md5
- name: コンフィグのmd5sumと比較
fail:
msg: "### {{ item.name }}のmd5sumが一致しません ###"
failed_when: item.md5sum != file_md5.results[index].ansible_facts.md5sum_result
loop: "{{ files }}"
loop_control:
index_var: indexタスクの解説です。まず、loopにコンフィグのハッシュキー"files"を指定し、コンフィグからファイルの情報を収集し、md5sumを実行します。
実行結果はfile_md5_result(配列)に保持します。changed_whenは、md5sum実行でchanged=1となるのを抑止しています。
- name: ファイルのmd5sum実行
command: "md5sum {{ item.path }}/{{ item.name }}"
loop: "{{ files }}"
register: file_md5_result
changed_when: false次に実行結果file_md5_resultをloop変数に指定し、splitを使ってmd5sum値のみを収集し、set_factを使って変数"md5sum_result"に設定します。
- name: ファイルのmd5sum結果取得
set_fact:
md5sum_result: "{{ item.stdout.split(' ')[0] }}"
loop: "{{ file_md5_result.results }}"
register: file_md5最後に、もう一度loopにコンフィグのハッシュ"files"を指定し、
- name: コンフィグのmd5sumと比較
fail:
msg: "### {{ item.name }}のmd5sumが一致しません ###"
failed_when: item.md5sum != file_md5.results[index].ansible_facts.md5sum_result
loop: "{{ files }}"
loop_control:
index_var: indexfailed_whenは、指定した条件がTrueのとき、タスクを失敗させる条件を定義します。
ここでは、コンフィグのmd5sum値と配列変数に保持したmd5sum値が等しくない場合にタスクを失敗させます。
タスクを失敗させた場合にfailが発動し、msgに指定した文字列を出力します。
「index_var: index」は、ループのインデックス(0から始まる番号)を"index"という変数として利用できるようにしています。
これを使うことで、配列変数"file_md5.results"をインデックスを使って順に参照できます。
bashスクリプトでCSVファイルを読み込む方法
bashスクリプトでCSVファイルを読み込む方法を紹介します。
1.問題点
bashスクリプトで大量CSVのデータを読み込む必要が生じましたが、読み込む方法がわかりません。
ということで、bashスクリプトでCSVファイルを読み込む方法を紹介します。
2.bashスクリプトでCSVファイルを読み込む
ここではCSVファイルに「名前」「ユーザー名」「パスワード」を3件設定したファイル(sample.csv)を読み込むものとします。
山田,yamada,GU2LTgyM
鈴木,suzuki,Njg4ZWYz
佐藤,sato,b291bf53bashスクリプト(test.sh)でCSVファイルを読み込むには次のようにします。
#!/bin/bash
# 引数でCSVファイル名を取得
input_file="$1"
# CSVファイルを行ごとに読み込み
while IFS=',' read -r NAME USER PASS; do
echo "名前: $NAME"
echo "ユーザー名: $USER"
echo "パスワード: $PASS"
# ここに必要な処理を追加
done < "$input_file"これでCSVファイルの内容が1行ずつ読み込まれ、変数$NAME,$USER,$PASSにそれぞれ格納されます。
あとは、必要な処理をその中に追加すればOKです。
実行結果
$ ./test.sh sample.csv
名前: 山田
ユーザー名: yamada
パスワード: GU2LTgyM
名前: 鈴木
ユーザー名: suzuki
パスワード: Njg4ZWYz
名前: 佐藤
ユーザー名: sato
パスワード: b291bf53引数が設定されていない場合のチェックを行うには、赤字の処理を追加します。
#!/bin/bash
# 引数でCSVファイル名を取得
input_file="$1"
# 引数が指定されていない場合のエラーメッセージ
if [[ -z "$input_file" ]]; then
echo "使用法: $0 <CSVファイル名>"
exit 1
fi
# CSVファイルを行ごとに読み込み
while IFS=',' read -r NAME USER PASS; do
echo "名前: $NAME"
echo "ユーザー名: $USER"
echo "パスワード: $PASS"
# ここに必要な処理を追加
done < "$input_file"さらに、CSVファイルにコメント行や空行が含まれる場合は赤字の処理を追加します。
#!/bin/bash
# 引数でCSVファイル名を取得
input_file="$1"
# 引数が指定されていない場合のエラーメッセージ
if [[ -z "$input_file" ]]; then
echo "使用法: $0 <CSVファイル名>"
exit 1
fi
# CSVファイルを行ごとに読み込み
while IFS=',' read -r NAME USER PASS; do
# 空行やコメント行はスキップ
if [[ -z "$NAME" || "$NAME" =~ ^# ]]; then
continue
fi
echo "名前: $NAME"
echo "ユーザー名: $USER"
echo "パスワード: $PASS"
# ここに必要な処理を追加
done < "$input_file"
